
はじめに
ある日突然、あなたが翻訳APIを提供する立場になったとします。どのようなシステム設計を行いますか?
ゼロからモデルを訓練する人は少ないと思います。最も簡単なのは、DeepL APIやCloud Translation APIをそのまま利用してもらうか、それらをラップすることでしょうか。LLMを利用する場合は、プロンプトをカスタマイズして簡単にAPIを公開できるDifyのようなプラットフォームもあります。
私は翻訳APIを収益化しない用途*1で提供しているため、新たな選択肢としてCloudflare Workers AIに注目しています。本記事では、Cloudflare Workers AIで翻訳モデルを実行するための周辺知識と実際の手順を紹介します。
1. Cloudflare Workers AIとは
簡単に言うと、Cloudflareのエッジネットワーク上でモデルを実行できるAI推論用のプラットフォームです。
Modelsからモデルの一覧を見ることができます。人気のあるオープンソースのモデルが多くサポートされていました。
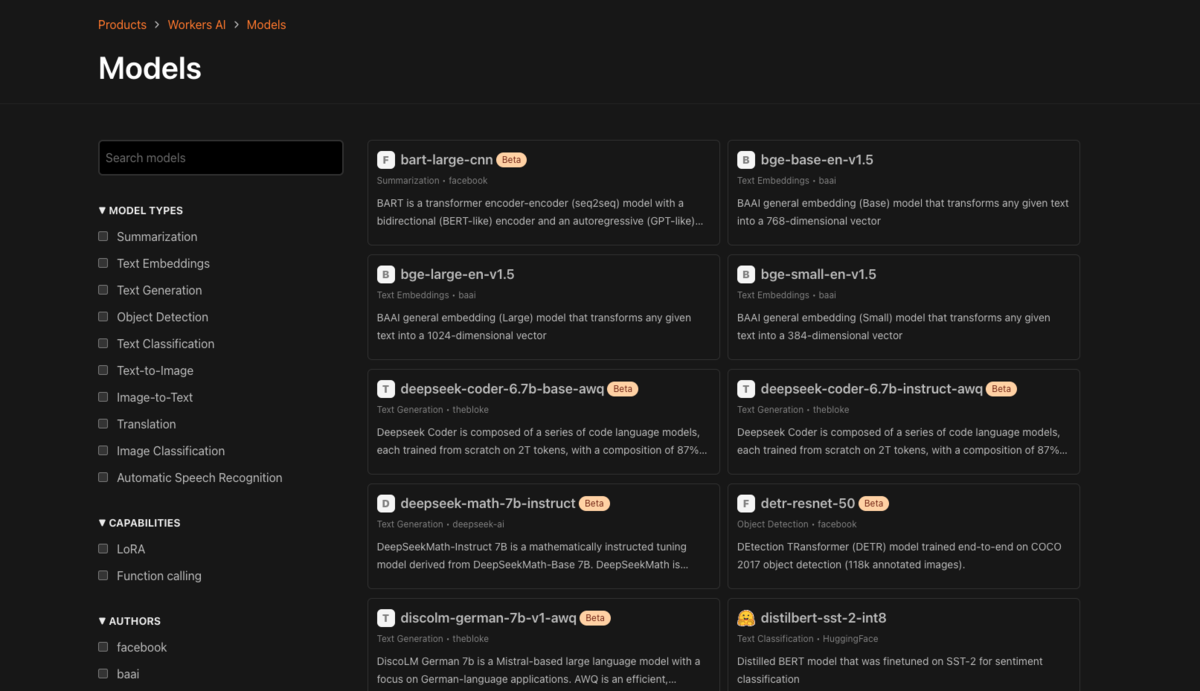
Workers AIの公式ドキュメントを一通り読んだので、ポイントをいくつか紹介します。
- WorkersのFreeプランとPaidプランの両方に含まれており、モデルのタスク・サイズ・ユニットによって決まる
- CLI / REST API / Dashboardの3通りの方法でデプロイできる
- Text Generationには、ロール(役割)と内容を入力するScopedプロンプトと、単一の質問を入力すると自動的にScopedに変換するUnscopedプロンプトの2種類がある
- LoRAファインチューニングやFunction callingもサポートしている
- 既存のWorkerにWorkers AIをバインドできる
- Text GenerationのPlaygroundで全てのモデルを実行できる
想像していたよりも多くのことがWorkers AIで実現できそうです。
Get startedでは、「Hello Worldの語源は?」をLLMのプロンプトに指定するようなアプリケーションを作成していました。
無料枠内だと思いますが、Workers AIを利用するとローカル開発でも使用量が発生する可能性があるので注意してください。
2. HonoでWorkers入門
1章ではシンプルなTypeScriptを使用してWorkerを実行しました。一方で、最近話題のHonoというフレームワークもCloudflare Workers上で実行できるそうです。
せっかくなのでHonoに入門しつつ、翻訳APIのベースラインを作成します。
まずは公式ドキュメントの通り、僅か3ステップでローカル開発環境が整いました。

Contextオブジェクトが便利
本記事の目標は翻訳APIを提供することなので、DeepL APIのAPIリファレンスにあるリクエストパラメータを参考にしつつ以下のように実装しました(src/indext.ts)。
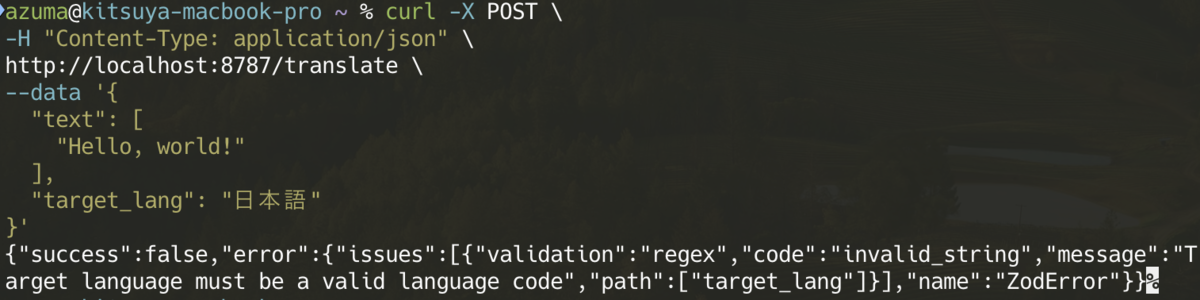
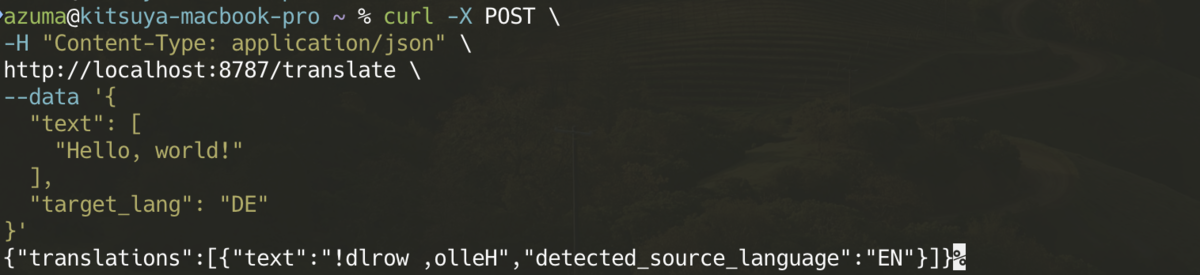
import { zValidator } from "@hono/zod-validator"; import { Hono } from "hono"; import { z } from "zod"; const app = new Hono(); const schema = z.object({ text: z.array(z.string()).nonempty("Text is required"), source_lang: z .string() .optional() .default("EN") .refine( (lang) => !lang || /^[A-Z]{2}$/.test(lang), "Source language must be a valid language code or omitted" ), target_lang: z .string() .min(2, "Target language code is required") .regex( /^[A-Z]{2}(-[A-Z]{2,4})?$/, "Target language must be a valid language code" ), }); app.post("/translate", zValidator("json", schema), (c) => { const data = c.req.valid("json"); const translations = data.text.map((text) => { const translatedText = text.split("").reverse().join(""); return { text: translatedText, detected_source_language: data.source_lang, }; }); return c.json({ translations, }); }); export default app;
実際には翻訳は行わず、暫定的に反転させた文字列をレスポンスとしています。
また、Zod Validator Middlewareを利用してバリデーションを行いました。Zodには初めて触れましたが、非常に開発者体験が良いライブラリだと思いました。
Honoには他にも色々なミドルウェアがあって楽しいので、今回は利用しませんが認証系を特にやってみたいです。
3. Workers AIで翻訳モデルを実行
さて、いよいよWorkers AIを利用して翻訳モデルを実行します。
wangler.tomlの以下の部分のコメントアウトを外して、yarn run wrangler typesで型を生成します。
[ai] binding = "AI"
$ yarn run wrangler types # 省略 ⛅️ wrangler 3.99.0 ------------------- Generating project types... interface Env { AI: Ai; } ✨ Done in 2.07s. $ yarn add @cloudflare/ai # 省略
モデルとしては、執筆時点で唯一のTranslationモデルであるm2m100-1.2bを使用します。
src/index.tsの2章との差分を以下に示します。
// 省略 + import { Ai } from "@cloudflare/ai"; + type Bindings = { + AI: any; + }; - const app = new Hono(); + const app = new Hono<{ Bindings: Bindings }>(); // 省略 - app.post("/translate", zValidator("json", schema), (c) => { + app.post("/translate", zValidator("json", schema), async (c) => { const data = c.req.valid("json"); + const ai = new Ai(c.env.AI); - const translations = data.text.map((text) => { - const translatedText = text.split("").reverse().join(""); - return { - text: translatedText, - detected_source_language: detectedSourceLanguage, - }; - }); + const translations = await Promise.all( + data.text.map(async (text) => { + const response = await ai.run("@cf/meta/m2m100-1.2b", { + text: text, + source_lang: data.source_lang.toLowerCase(), + target_lang: data.target_lang.toLowerCase(), + }); + return { + text: response.translated_text, + detected_source_language: data.source_lang, + }; + }) + ); return c.json({ translations, }); }); export default app;
m2m100-1.2bのモデル出力としてはターゲット言語の翻訳テキストしか得られないので、DeepL APIのようにソース言語を検出することはできません。ソース言語の検出機能が必要な場合、Text Generationモデルに適切なプロンプトを入力する方法も考えられますが、レスポンスタイムや出力形式の懸念があるため一旦断念します。
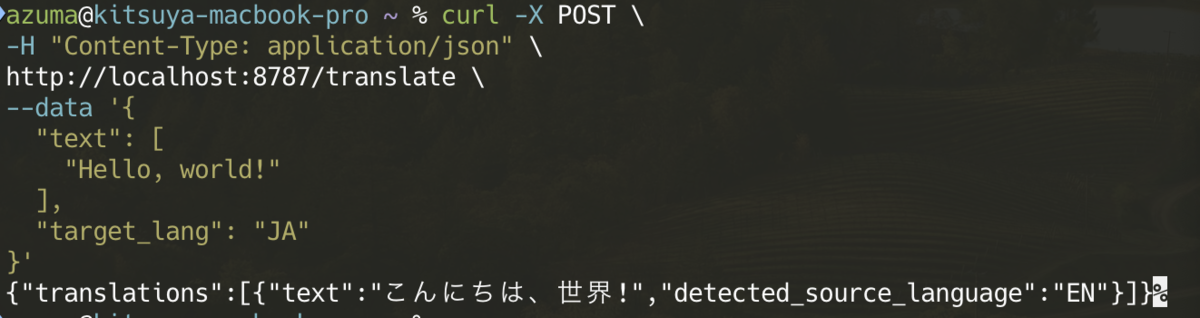
問題なく翻訳されたテキストがレスポンスとして返ってきました。
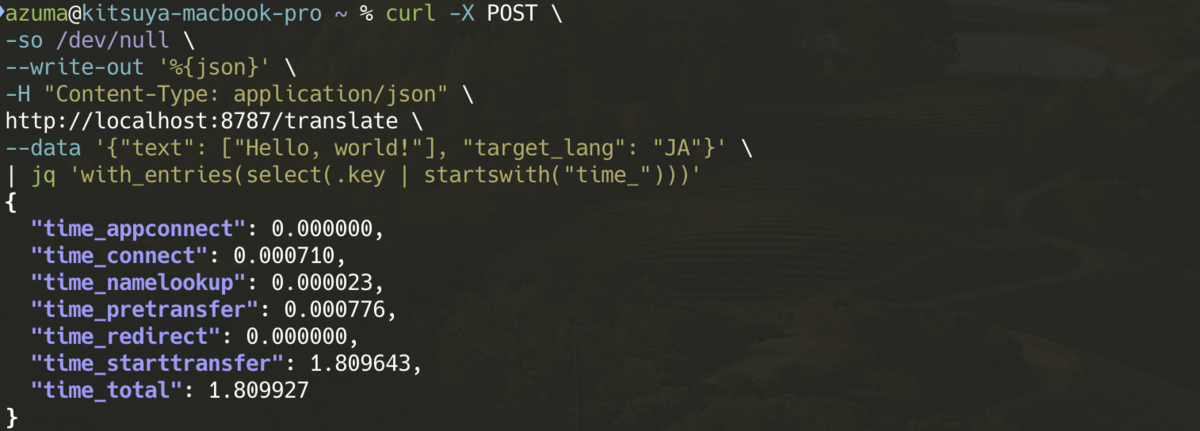
レスポンスタイムはおよそ2秒弱で、体感はDeepL APIと同じくらいでした。
最後にyarn deployで一瞬のうちにデプロイして完成です。
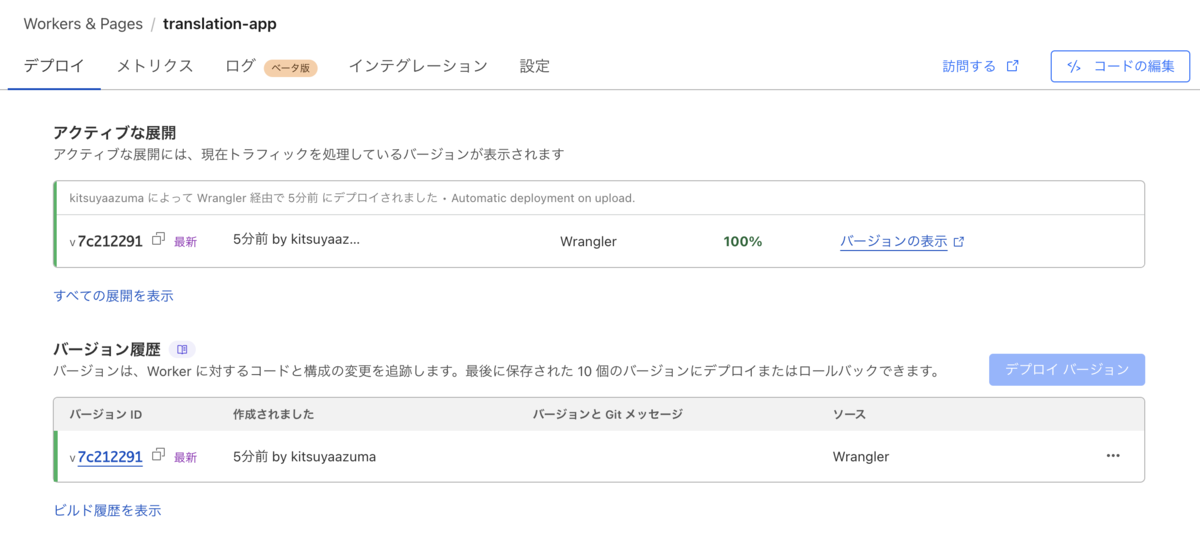
4. AI Gatewayによるレート制限
3章でデプロイまで完了しましたが、ダッシュボードを確認すると着実にFreeプランの使用制限を蝕んでいることが分かります。
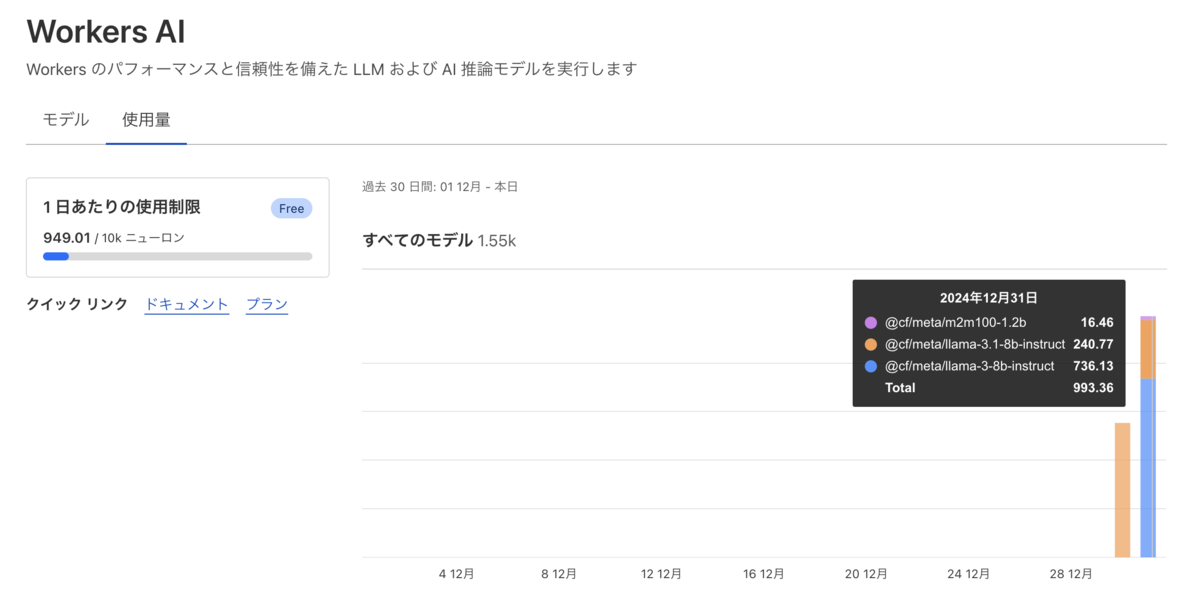
本記事では不特定多数の人に翻訳APIを提供する目的なので、ユーザーの悪意の有無に関わらずレート制限は設定するべきです。
2024年4月にGAになったAI Gatewayは、Workers AIの可視化(アナリティクス、ロギング)と制御(キャッシング、レート制限、リトライ・フォールバックなど)を可能にします。
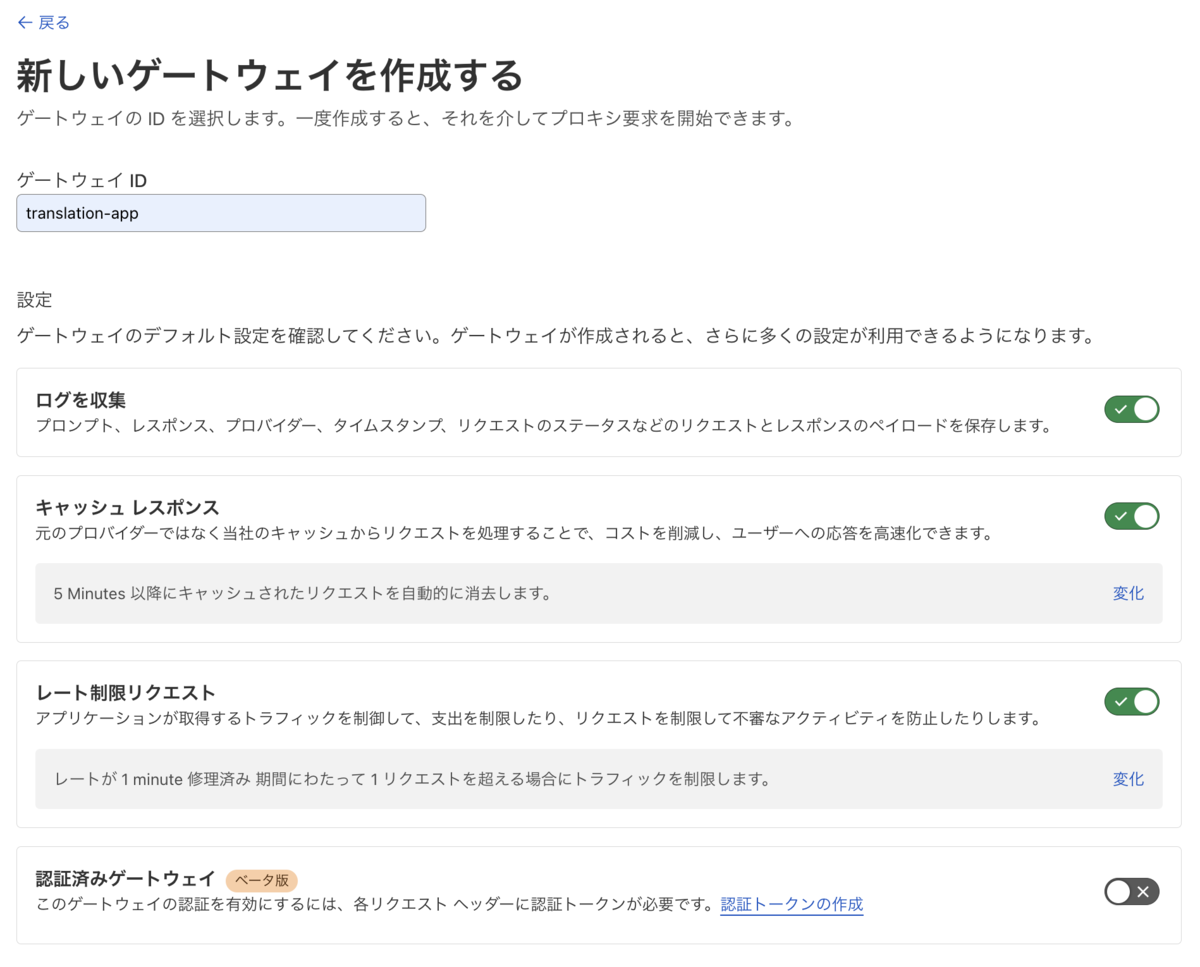
Workers BindingにおけるAI Gatewayのセットアップは上記の公式ドキュメントに記載されていますが、小さな落とし穴があったので簡単に紹介します。
次にsrc/index.tsを以下のように変更します。
// 省略 import { Ai } from '@cloudflare/workers-types' // (1) type Bindings = { AI: Ai // (1) } const app = new Hono<{ Bindings: Bindings }>() const schema = z.object({ // 省略 }) app.post('/translate', zValidator('json', schema), async (c) => { const data = c.req.valid('json') let isRateLimited = false const translations = await Promise.all( data.text.map(async (text) => { try { const response = await c.env.AI.run( '@cf/meta/m2m100-1.2b', { text: text, source_lang: data.source_lang.toLowerCase(), target_lang: data.target_lang.toLowerCase(), }, { gateway: { // (2) id: 'translation-app', }, } ) return { text: response.translated_text, detected_source_language: data.source_lang, } } catch (error: unknown) { if (error instanceof Error) { if (error.name === 'AiError' && error.message === '2003: Rate limited') { isRateLimited = true // (3) } return { error: error.message } } return { error: 'Unknown error' } } }) ) if (isRateLimited) { // (3) return c.newResponse('Rate limited', { status: 429 }) } return c.json({ translations }) }) export default app
ポイントは大きく分けて3つあります。
(1) My first Cloudflare Workers AIを参考に、3章ではtype BindingsでAI: anyとした上で、@cloudflare/aiからimportしたAiでconst ai = new Ai(c.env.AI)としていましたが、ai.run()の引数にGatewayOptionsを指定できなくなるので、@cloudflare/workers-typesからimportしています。
@cloudflare/ai/dist/sdk.d.tsの抜粋
export type AiOptions = { debug?: boolean; prefix?: string; extraHeaders?: object; overrideSettings?: object; fetchUrl?: string; };
export declare class Ai { private binding; private options; private logs; lastRequestId: string; constructor(binding: any, options?: AiOptions); run<M extends ModelName>(model: M, inputs: ConstructorParametersForModel<M>): Promise<GetPostProcessedOutputsType<M>>; getLogs(): string[]; }
@cloudflare/workers-types/2023-07-01/index.tsの抜粋
export type AiOptions = { gateway?: GatewayOptions; prefix?: string; extraHeaders?: object; };
export declare abstract class Ai<ModelList extends ModelListType = AiModels> { aiGatewayLogId: string | null; gateway(gatewayId: string): AiGateway; run<Name extends keyof ModelList>( model: Name, inputs: ModelList[Name]["inputs"], options?: AiOptions, ): Promise<ModelList[Name]["postProcessedOutputs"]>; } export type GatewayOptions = { id: string; cacheKey?: string; cacheTtl?: number; skipCache?: boolean; metadata?: Record<string, number | string | boolean | null | bigint>; collectLog?: boolean; };
(2) gatewayのidはCloudflareのダッシュボード上で確認できます。idのみ必須ですが、他にもskipCacheやcacheTtlなどを指定できます。
(3) Cloudflareのダッシュボード上で設定したレート制限を超えた場合、ステータスコード429で'Rate limited'をレスポンスを返すようにしました(本当はエラーハンドリングにinstanceofを使いたかったですが、上手くいきませんでした)。
実際にローカルサーバーで検証してみます。
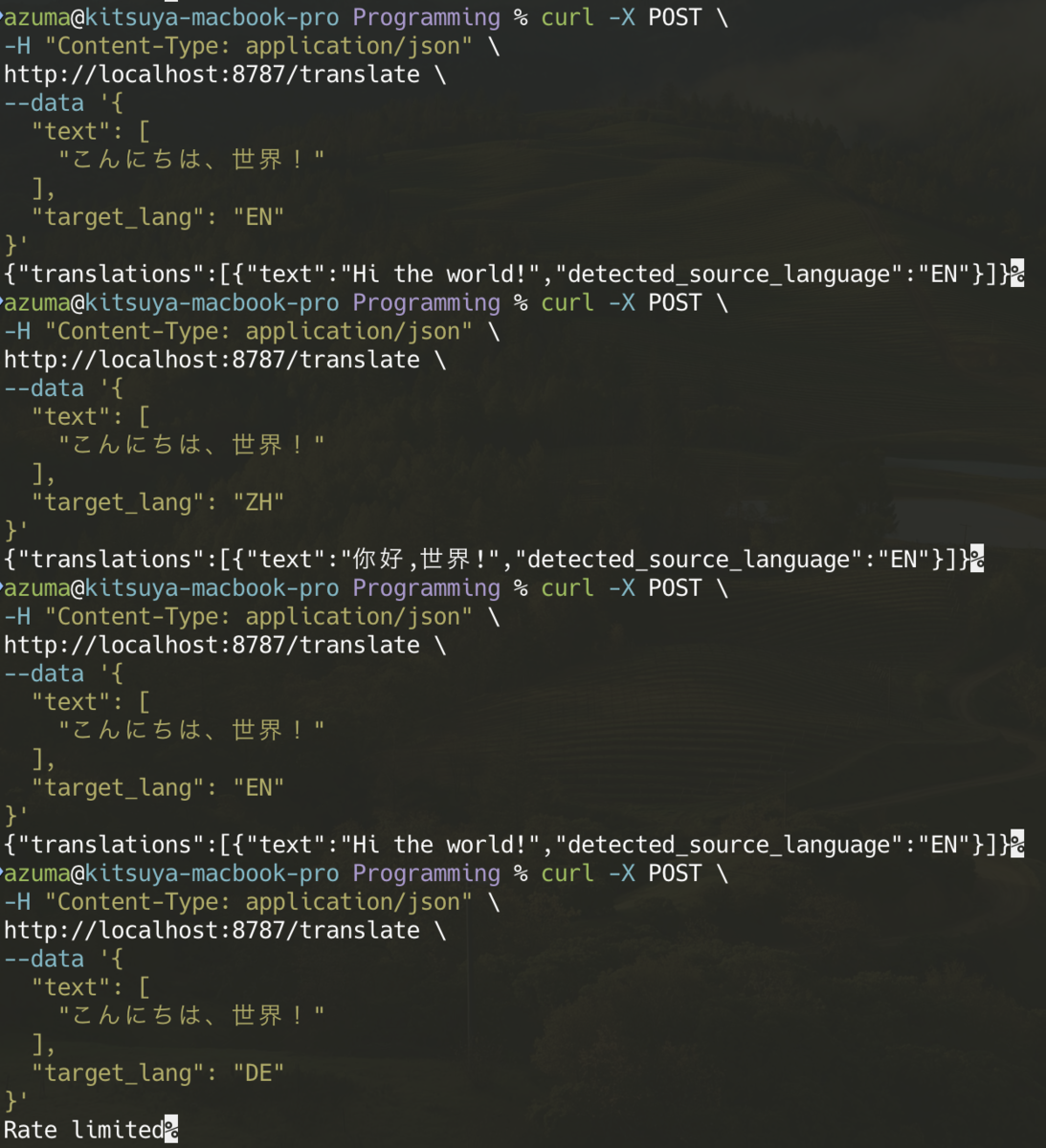
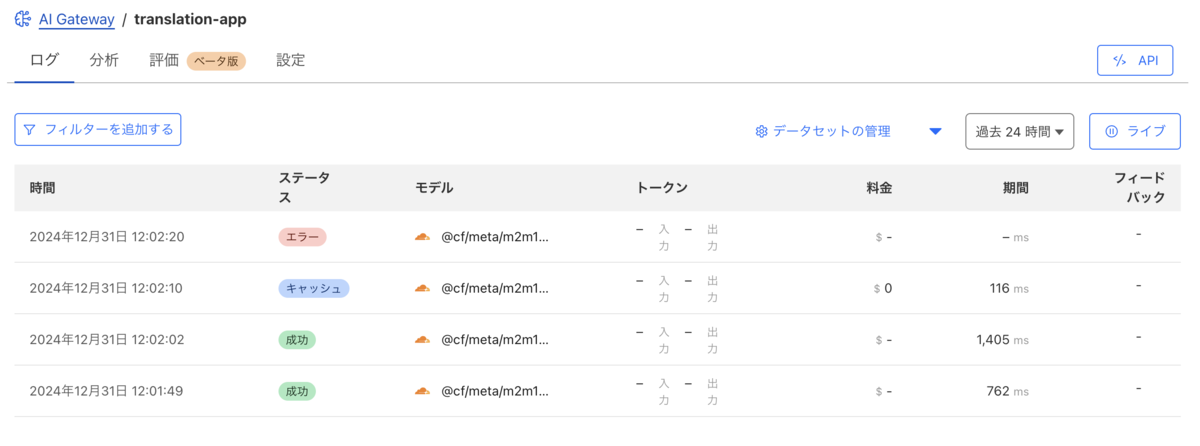
レート制限とレスポンスキャッシュを適用することができましたが、Workers AIの使用制限は「ニューロン」で測定されます。
ニューロンは、AIの出力を測定する方法であり、常にゼロにスケールダウンする(使用量がゼロの場合、0ニューロン分の料金が課金される)。 1,000個のニューロンで何ができるかというと、130個のLLM応答、830個の画像分類、1,250個の埋め込みを生成できる。
ユーザーが1回のリクエストで長いテキストを入力する場合、大量のニューロンを消費する可能性が高いので、適度に文字列長(理想はトークン数)を制限しても良いと思いました。
まとめ
Cloudflare Workers AIで翻訳モデルを実行する方法を紹介しました。
私は今までCloudflareのドメイン管理とTunnelsしか利用していませんでしたが、Freeプランが充実していて開発者体験も最高なので今回もっと好きになりました。また、HonoとZodも今回初めて利用しましたがコンセプトがとても素敵なので今後も積極的に利用していきたいと思います。
P.S. 2024年最後の記事になりました。2025年もやっていき!
*1:改訂2版の公開が迫っているReactではじめるChrome拡張開発入門のハンズオン環境を提供するためです