
はじめに
ある日、特定の研究室サーバーに対してSSH接続できなくなったことがありました。このような問題は今回が初めてではなく、似たような事例が発生しては「面倒なので再起動する」という対応を取っていました。
一方、少しでも手掛かりがあるならば根本的に問題を解決してみたいと以前から考えていました*1。
本記事では、監視の定番であるPrometheus・Grafana・Alertmanagerを導入する方法を紹介します。いずれも私が以前所属していた研究室で導入した経験があるため、Getting Startedというよりは導入の改善に焦点を当てたいと思います。
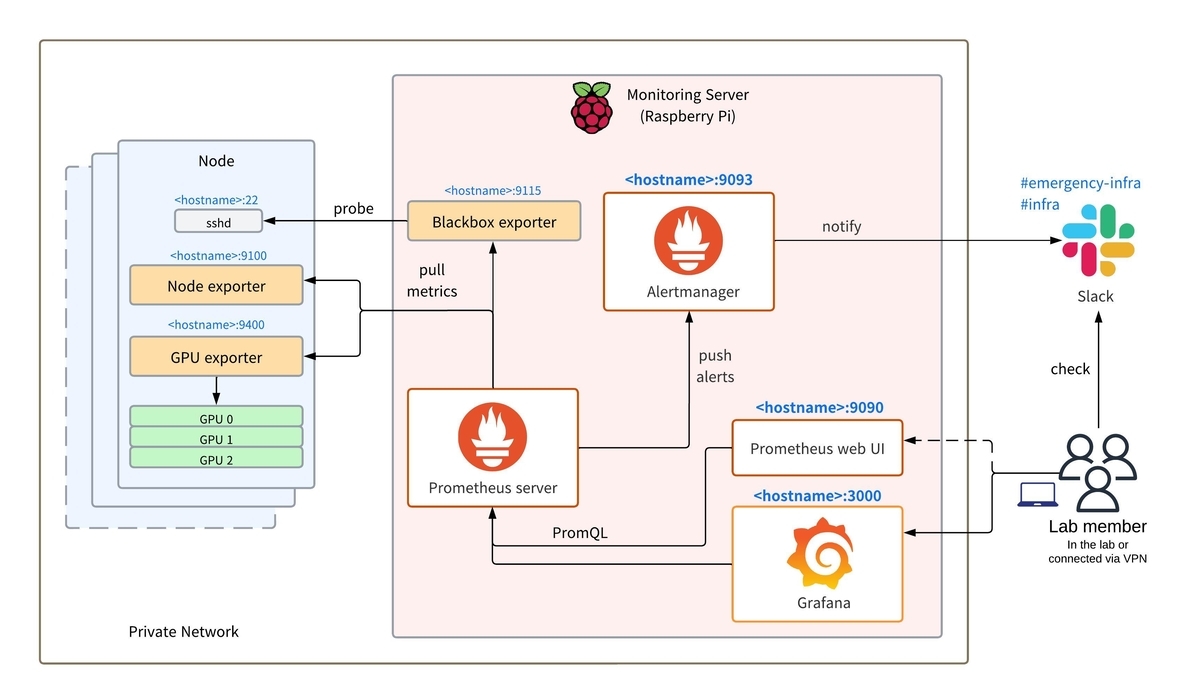
1. Prometheusによる監視
1-1. Node exporter
まず、ハードウェアやOSのメトリクスを公開するためにNode exporterを監視対象ノードにインストールします。
インストールを行う際、バイナリインストールは軽量かつシンプルでサービス化しやすいというメリットがあります。しかし、バイナリはアップデートやドキュメント化が個人的に面倒だと感じるので、Dockerでのインストールをオススメします。
infra@DLBox-Alpha:~$ docker run -d \ --net="host" \ --pid="host" \ --name=node-exporter \ --restart=always \ -v "/:/host:ro,rslave" \ quay.io/prometheus/node-exporter:latest \ --path.rootfs=/host
基本はREADMEの通りですが、--restartオプションを使用することで再起動ポリシーを指定しています。ここではalwaysとして終了ステータスに関係なく常にコンテナを再起動させます。
興味深いのはコンテナ内からホストを監視しているという点です。ホスト側のネットワークやPID名前空間を使用し、/ディレクトリをマウントした上で--path.rootfsオプションによってホストのルートディレクトリがマウントされている場所をを指定しています。
エンドポイントを叩いてメトリクスを取得できれば確認完了です。
infra@DLBox-Alpha:~$ curl -s localhost:9100/metrics | head # HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles. # TYPE go_gc_duration_seconds summary go_gc_duration_seconds{quantile="0"} 1.7022e-05 go_gc_duration_seconds{quantile="0.25"} 3.3243e-05 go_gc_duration_seconds{quantile="0.5"} 3.9886e-05 go_gc_duration_seconds{quantile="0.75"} 4.5357e-05 go_gc_duration_seconds{quantile="1"} 8.0594e-05 go_gc_duration_seconds_sum 4.64771644 go_gc_duration_seconds_count 95781 # HELP go_goroutines Number of goroutines that currently exist.
1-2. Blackbox exporter
Blackbox exporterについては、私にとって今回が初めての導入です。一言で言うと、外形監視を行います。
『入門 監視 ―モダンなモニタリングのためのデザインパターン』という本では、ユーザー視点での監視が重要だと述べられていました。研究室サーバーのユーザー視点に立つと、(はじめにで紹介したような)サーバーにSSH接続できない状況は可能な限りゼロにしたいです。Blackbox exporterはSSHを含め、HTTP/HTTPS/DNS/TCP/ICMP/gRPCのエンドポイント監視をサポートしています。
通常、exporterは監視対象サーバーで動かしますが、Blackbox exporterは監視サーバー(Raspberry Pi)にインストールして動作させます。
infra@pi-monitor:~$ docker network create monitoring-network infra@pi-monitor:~$ docker run -d \ -p 9115:9115/tcp \ --name blackbox-exporter \ --network monitoring-network \ -v /etc/blackbox_exporter/blackbox.yml:/config/blackbox.yml \ --restart always \ quay.io/prometheus/blackbox-exporter:latest \ --config.file=/config/blackbox.yml
monitoring-networkというネットワークを作成し接続する理由は、後ほどPrometheusサーバーをインストールする時に分かりますが、コンテナ間通信を行うためです。
また、監視にはssh_bannerを使用するので、GitHubリポジトリ内のblackbox.ymlをそのまま設定ファイル(/etc/blackbox_exporter/blackbox.yml)として問題なさそうです*2。
Blackbox exporter自身のメトリクスが取得できれば、起動していることが確認できます。
infra@pi-monitor:~$ curl -s localhost:9115/metrics # 省略
1-3. GPU exporter
NVIDIA GPUのメトリクスを公開するexporterとしては以下の2つが有名です。
両者ともにGitHubのスター数は800ほど(執筆時点)と拮抗していますが、前者は個人OSSであり「メンテナンス時間の確保が難しい」と明記されています。また、以前はGrafanaダッシュボードのデザインがカッコいいという理由だけで前者を採用しましたが、GPUのUUID*3でダッシュボードを変数フィルタリングしなければならず、Forkして独自の修正を行なっていました。
今回はNVIDIAがメンテナンスを行なっている後者を採用します。コンテナが起動したら、これまでと同様にメトリクスを取得できるかを確認してください。
infra@DLBox-Alpha:~$ docker run -d \ --gpus all \ --restart always \ -p 9400:9400 \ --name dcgm-exporter \ nvcr.io/nvidia/k8s/dcgm-exporter:3.3.7-3.5.0-ubuntu22.04 infra@DLBox-Alpha:~$ curl -s localhost:9400/metrics # 省略
1-4. Prometheus
いよいよPrometheusサーバー自身を監視サーバー(Raspberry Pi)にインストールします。
infra@pi-monitor:~$ docker run -d \ -p 9090:9090 \ --name prometheus \ --network monitoring-network \ -v /etc/prometheus:/etc/prometheus \ -v /etc/hosts:/etc/hosts:ro \ --restart always \ prom/prometheus \ --config.file=/etc/prometheus/prometheus.yml \ --web.enable-lifecycle
/etc/hostsを読み込み専用でマウント*4しているのは、監視対象をホスト名で指定して名前解決を行った方がGrafanaダッシュボードの変数フィルタリングが理解しやすくなるためです。
私の場合はホストマシンの/etc/prometheus/prometheus.ymlに以下のような設定ファイルを置いてマウントしています。
global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'prometheus' scrape_interval: 5s static_configs: - targets: ['localhost:9090'] - job_name: 'node-exporter' scrape_interval: 15s static_configs: - targets: - 'DLBox-Alpha:9100' - 'DLBox-II:9100' - 'DLBox-Gamma:9100' - job_name: 'blackbox' scrape_interval: 15s metrics_path: /probe params: module: [ssh_banner] static_configs: - targets: - 'DLBox-Alpha:22' - 'DLBox-Gamma:22' - 'DLBox-II:22' relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: blackbox-exporter:9115 # The blackbox exporter's real hostname:port. - job_name: 'blackbox-exporter' # collect blackbox exporter's operational metrics. static_configs: - targets: ['blackbox-exporter:9115'] - job_name: 'dcgm-exporter' scrape_interval: 15s static_configs: - targets: - 'DLBox-Alpha:9400' - 'DLBox-Gamma:9400' - 'DLBox-II:9400'
ここでいうDLBox-**は監視対象のGPUサーバーのホスト名なので各自変更してください。
内容はほとんどREADMEの通りですが、PrometheusコンテナもBlackbox exporterコンテナもmonitoring-networkに接続しているため、blackbox-exporter:9115のようにコンテナ名で名前解決できるのがポイントです。
コンテナが起動したら、ブラウザからhttp://<Raspberry PiのIPアドレス>:9090にアクセスしてPrometheusのWeb UIを確認します。
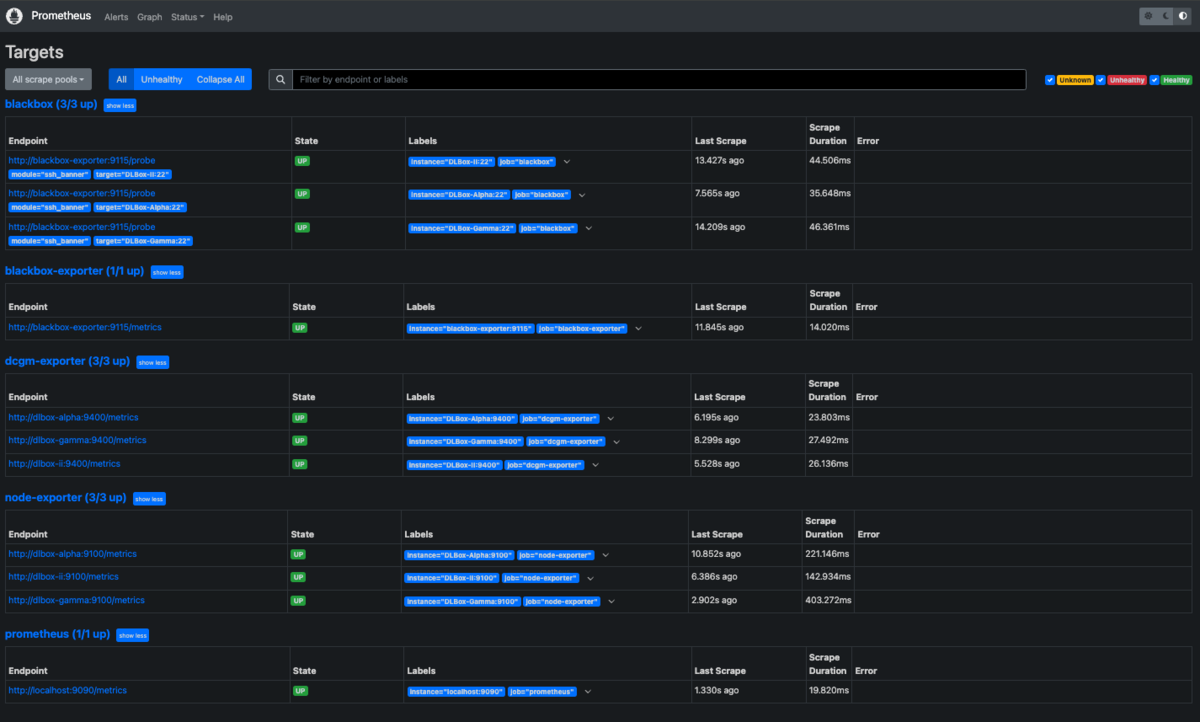
[Status]タブ→[Targets]を選択して、監視対象の情報を一覧表示してみます。
[Graph]タブで簡単な可視化ができますが、この後のGrafanaダッシュボードの感動を最大化するため、いつも通りスキップします。
2. Grafanaによる可視化
Prometheusをインストールした監視サーバー(Raspberry Pi)に、Grafanaもインストールします。
infra@pi-monitor:~$ docker run -d \ --name=grafana \ --network monitoring-network \ -p 3000:3000 \ --restart always \ grafana/grafana-enterprise
コンテナが起動したら、ブラウザからhttp://<Raspberry PiのIPアドレス>:3000にアクセスしてadmin:adminでサインインします。
初めての方は、公式ドキュメントを参考にダッシュボード作成に入門するのもオススメです。今回は既存の美しいダッシュボードをインポートして利用します(参考)。
以下は作成するダッシュボードとそのID、実際のスクリーンショットです。
[1] Node Exporter Full(ID: 1860)
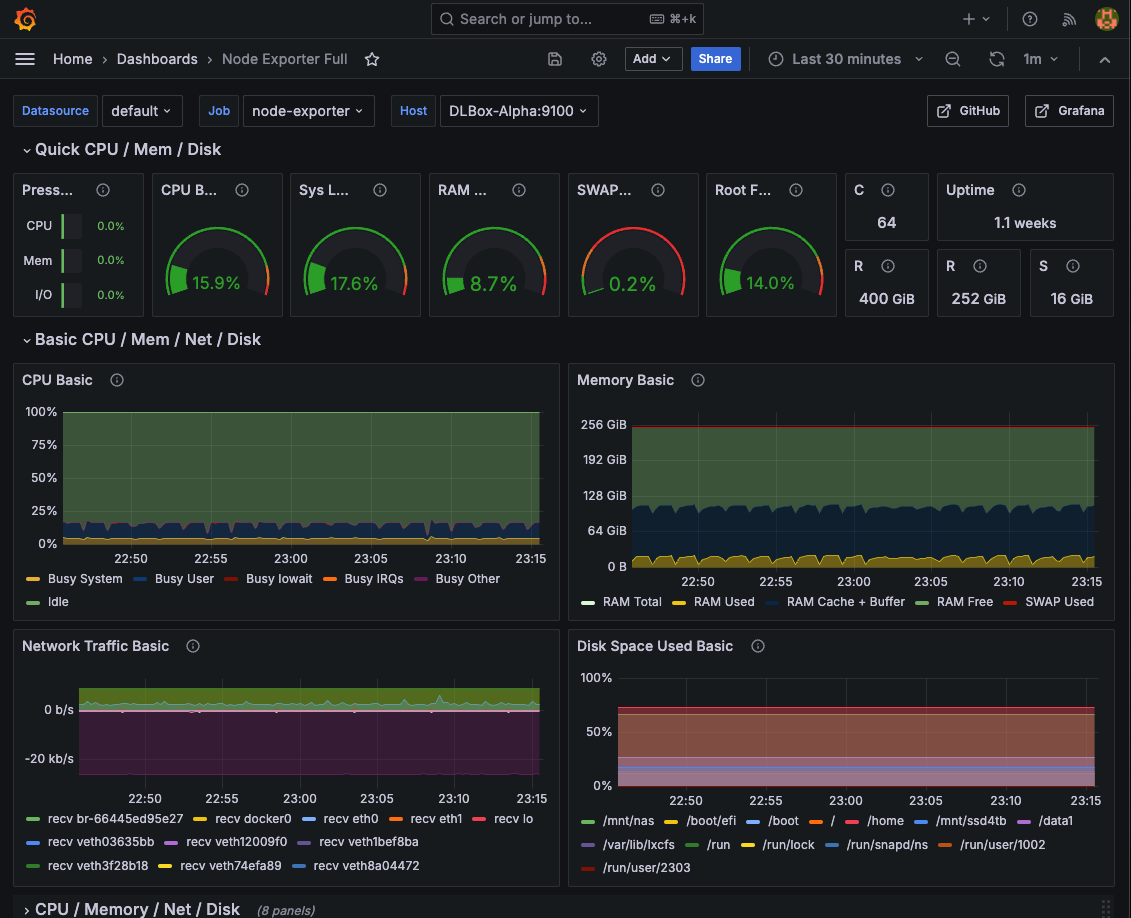
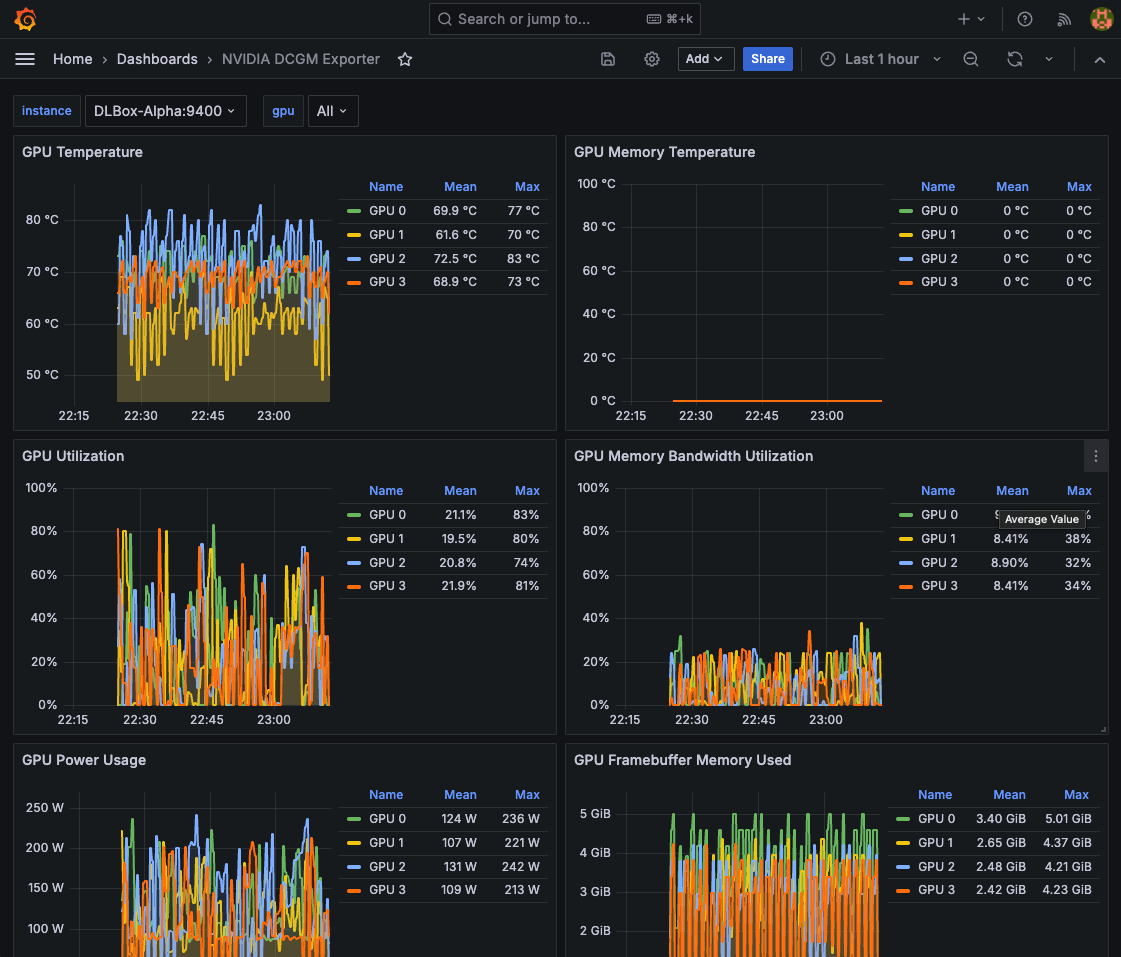
[2] NVIDIA DCGM Exporter(ID: 15117)
[3]【任意】Prometheus Blackbox Exporter(ID: 7587)
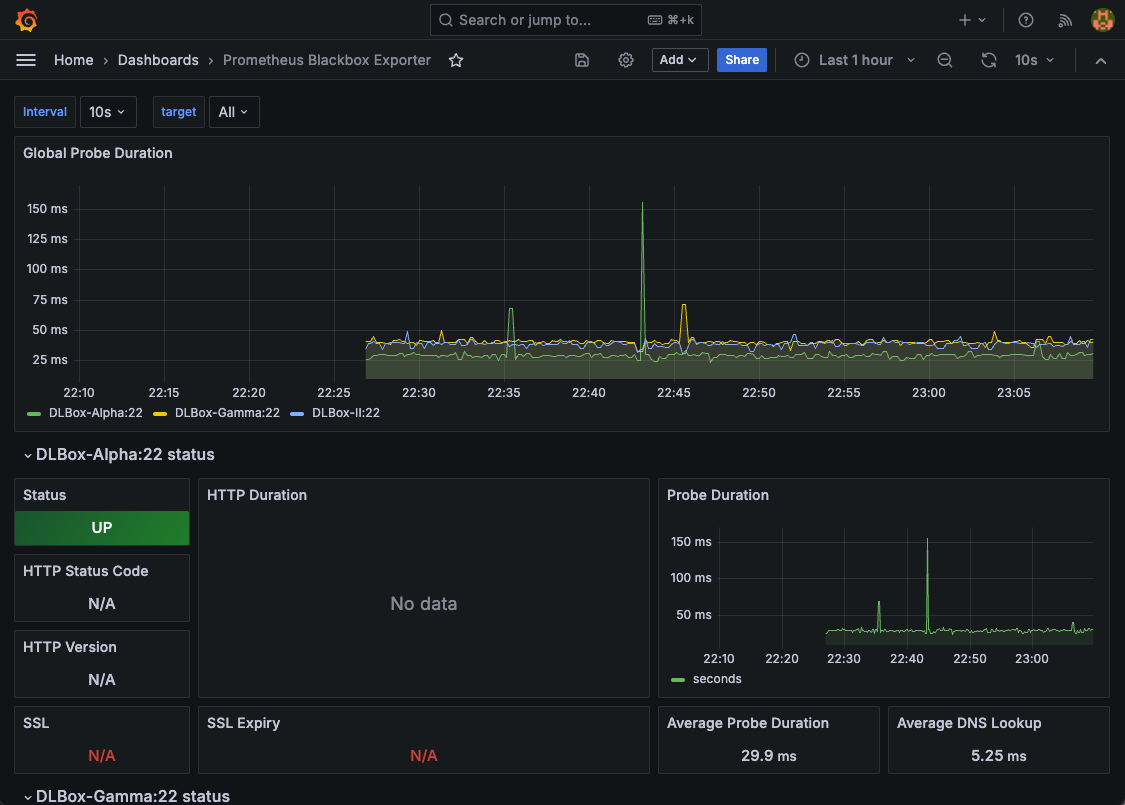
なお、ダッシュボードを作成する際にはData Soruceを指定する必要があります。今回はPrometheusを指定しますが、monitoring-networkに接続したコンテナ間通信なのでserver URLは迷わずhttp://prometheus:9090を指定できます。
さて、美しいダッシュボードは完成しましたが、ダッシュボードを眺めることが本来の目的ではありません。次の章でいよいよアラート通知の仕組みを整えます。
3. Alertmanagerによるアラート通知
最後に、Alertmanagerを監視サーバー(Raspberry Pi)にインストールします。
infra@pi-monitor:~$ docker run -d \ --name alertmanager \ --network monitoring-network \ --restart always \ -v /etc/alertmanager:/etc/alertmanager \ -p 9093:9093 \ quay.io/prometheus/alertmanager \ --config.file=/etc/alertmanager/alertmanager.yml \ --web.external-url=http://<Raspberry PiのIPアドレス>:9093
Alertmanagerの設定ファイルは以下の通りで、Slackの#infraと#emergency-infraという2つのチャンネルに重大度(severity)別に通知するようにしました。
# /etc/alertmanager/alertmanager.yml global: slack_api_url: https://hooks.slack.com/services/***** resolve_timeout: 5m route: receiver: 'default' group_by: ['alertname'] group_wait: 30s group_interval: 5m repeat_interval: 4h routes: - match: severity: critical receiver: 'slack-critical' - match: severity: warning receiver: 'slack-warning' receivers: - name: 'default' - name: 'slack-critical' slack_configs: - channel: '#emergency-infra' username: 'Alertmanager' send_resolved: true icon_emoji: ':prometheus:' text: '{{ if eq .Status "firing" }}{{ .CommonAnnotations.description }} {{else}}{{ .CommonAnnotations.resolved_description }}{{end}}' - name: 'slack-warning' slack_configs: - channel: '#infra' username: 'Alertmanager' color: '{{ if eq .Status "firing" }}warning{{ else }}good{{ end }}' send_resolved: true icon_emoji: ':prometheus:' text: '{{ if eq .Status "firing" }}{{ .CommonAnnotations.description }} {{else}}{{ .CommonAnnotations.resolved_description }}{{end}}'
infraチャンネルでドキドキしたくないので、発火した状態でも色は黄色(danger)にしているのが些細な工夫点です。
それから、アラートルールについては公式ドキュメントを参考に以下のように設定しました。SSH接続ができない状態が5分続いたらcritical、exporterがダウンしたらwarningとして定義しています。インフラは好きですが、別にアラートが好きという訳ではないのでアラート疲れを回避すべく最小限にしました。
# /etc/prometheus/alert_rules.yml groups: - name: instance rules: - alert: InstanceDown expr: up == 0 for: 5m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} down" description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes." resolved_description: "{{ $labels.instance }} of job {{ $labels.job }} is now back up." - name: ssh connection rules: - alert: SSHConnectionDown expr: probe_success{job="blackbox"} == 0 for: 5m labels: severity: critical annotations: summary: "SSH connection to {{ $labels.instance }} failed" description: "SSH connection to {{ $labels.instance }} for job {{ $labels.job }} has been down for more than 5 minutes." resolved_description: "SSH connection to {{ $labels.instance }} for job {{ $labels.job }} is now restored."
descriptionとresolved_descriptionを分けたのは、Slackの通知でアラートが解決した場合にも同じメッセージが添付されていると思わず2度見してしまうからです。
Prometheusの設定ファイルにはalerting:とrule_files:の項目を追加する必要があります。
# /etc/prometheus/prometheus.yml global: # 省略 alerting: alertmanagers: - static_configs: - targets: - alertmanager:9093 rule_files: - "/etc/prometheus/alert_rules.yml" scrape_configs: # 省略
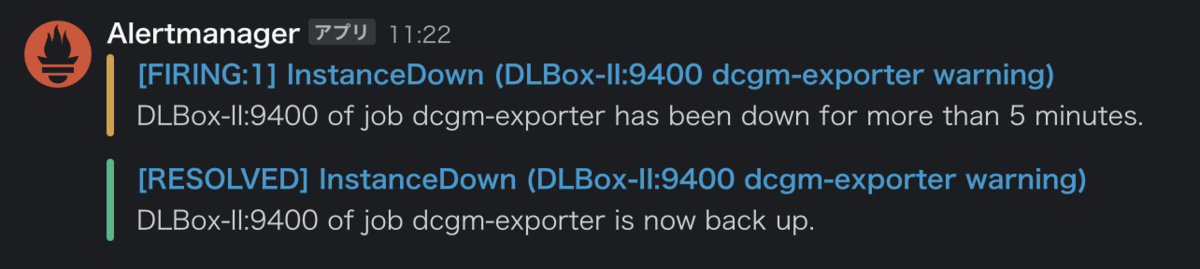
上記の変更が完了したら、docker restart prometheusでPrometheusサーバーを再起動します。試しに任意の監視対象サーバーでGPU exporterを一時停止してみましょう。
infra@DLBox-II:~$ docker pause dcgm-exporter # Slack通知が届くまで5分ほど待つ infra@DLBox-II:~$ docker unpause dcgm-exporter # Slack通知が届くまで5分ほど待つ
SSH接続ができない状況のアラート通知については、(ユーザーに迷惑をかけたくないので)Prometheusの設定ファイルをダミーのホスト名に変更することによってテストします。
infra@pi-monitor:~$ sed -i 's/DLBox-II:22/DLBox-III:22/' /etc/prometheus/prometheus.yml infra@pi-monitor:~$ curl --request POST "http://localhost:9090/-/reload" # Slack通知が届くまで5分ほど待つ infra@pi-monitor:~$ sed -i 's/DLBox-III:22/DLBox-II:22/' /etc/prometheus/prometheus.yml infra@pi-monitor:~$ curl --request POST "http://localhost:9090/-/reload" # Slack通知が届くまで5分ほど待つ
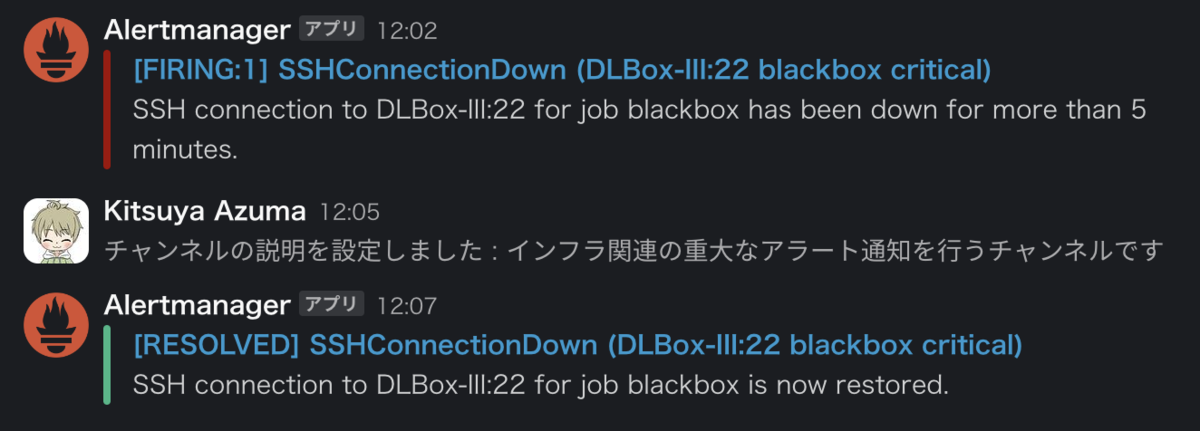
このAlertmanagerによるアラート通知をきっかけに、これからはPrometheusやGrafanaなどを駆使して障害対応に取り組もうと思います。
まとめ
本記事では、研究室サーバーにPrometheus・Grafana・Alertmanagerを導入し、監視の枠組みを完成させました。
インストール自体は単純作業ですが、PrometheusはKubernetesとも親和性が高いので興味を持った方はぜひ以下の本も読んでみてください。非常に分かりやすく、面白いです。
監視については、しばらく運用して課題が見つかったら改善して記事にしようと思います。
*1:今回は再起動後に/var/log/auth.log.1や/var/log/syslog.1を調べてみましたが原因までは分かりませんでした。
*2:level=error msg="Error loading config" err="error parsing config file: yaml: unmarshal errors:\n line 42: field labels not found in type config.plain"というエラーが出た場合は、該当するssh_banner_extractモジュールのlabelsフィールドをコメントアウトしてみてください。
*3:UUIDはnvidia-smi -LでGPU一覧とともに表示されます。
*4:監視対象でない対応付けも含まれているため、意図せず名前解決される可能性があります。その場合は、dockerコマンドの--add-hostオプションを検討してください。 https://docs.docker.com/reference/cli/docker/container/run/#add-host