はじめに
先日Xで以下のようなポストを見かけました。
Open Source LLM Tools
— elvis (@omarsar0) 2024年9月11日
If you are looking for useful open-source LLM tools, this is a really useful resource.
It includes different categories like tutorials, AI engineering, and applications, among others. You can also see the # of GitHub stars. pic.twitter.com/v6IGibvgBZ
少なくとも私のTLは数年前からChatGPTをはじめとするLLM関連の話題で持ちきりです。しかし、新しいツールの名前を目にする機会はあっても「どのような特徴があるか」「どのように利用できるか」を手元で動かしながら学ぶ時間は確保できていませんでした。
本記事では先述のランキングサイトを参考に、可能な限り手元でLLM関連のOSSを動かして感想を残したいと思います。
(注)2024年9月20日時点でのstar_7dすなわち7日間のスター数が多い順に紹介します。
- はじめに
- 1. Mintplex-Labs/anything-llm
- 2. lobehub/lobe-chat
- 3. OpenBMB/MiniCPM
- 4. ollama/ollama
- 5. f/awesome-chatgpt-prompts
- 6. mem0ai/mem0
- 7. ComposioHQ/composio
- 8. langflow-ai/langflow
- 9. comfyanonymous/ComfyUI
- 10. langgenius/dify
- まとめ
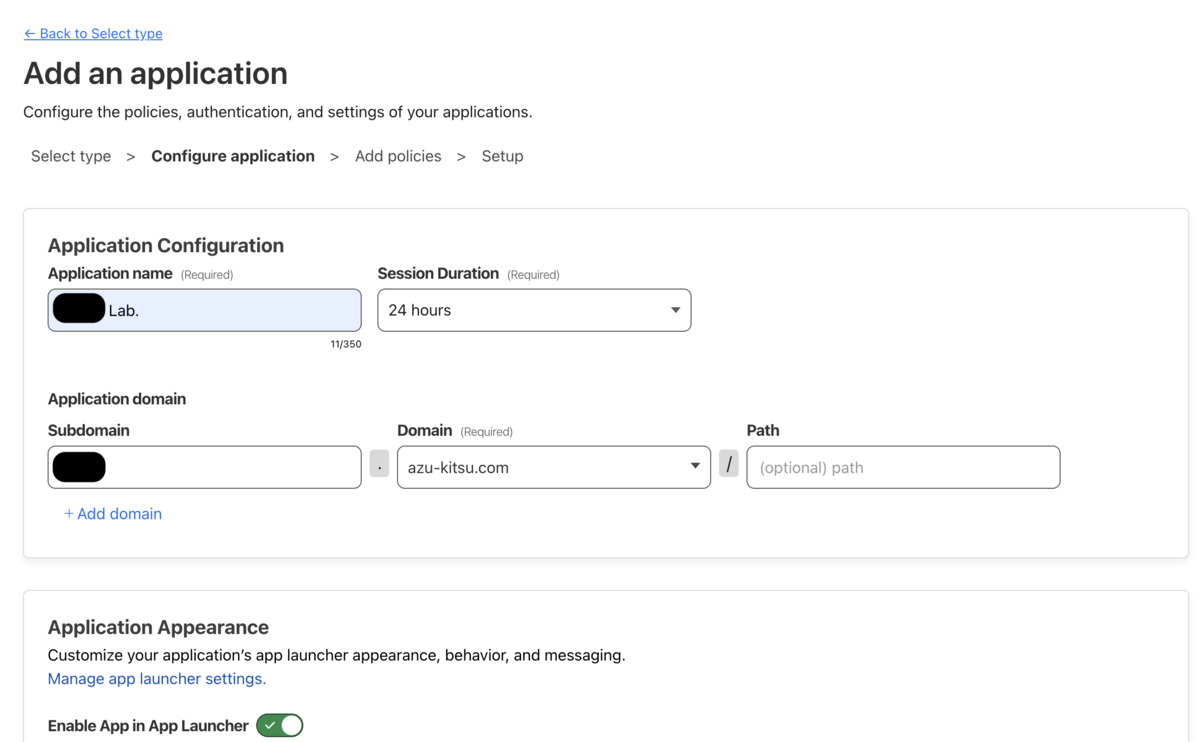
1. Mintplex-Labs/anything-llm
概要:closed LLM(OpenAIやAnthropicなど)やオープンソースLLM(Ollamaなど)とベクトルデータベースを自由に組み合わせることができ、ChatGPTのようなチャットUIを提供している。
手順:
Desktop版をMacbookにダウンロードすると、下図のようなチャットUIが利用できるようになった。
Workspace内ではドキュメントがコンテナ化されているため、コンテキストをクリーンに保てるとのこと。
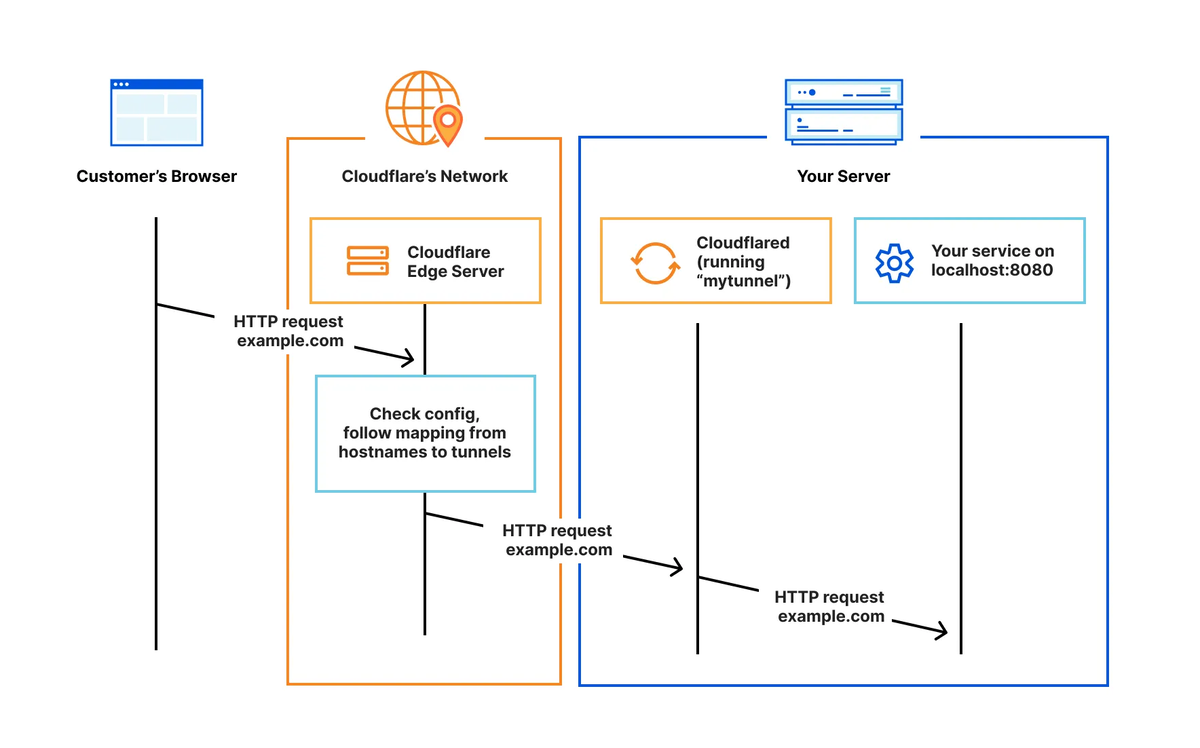
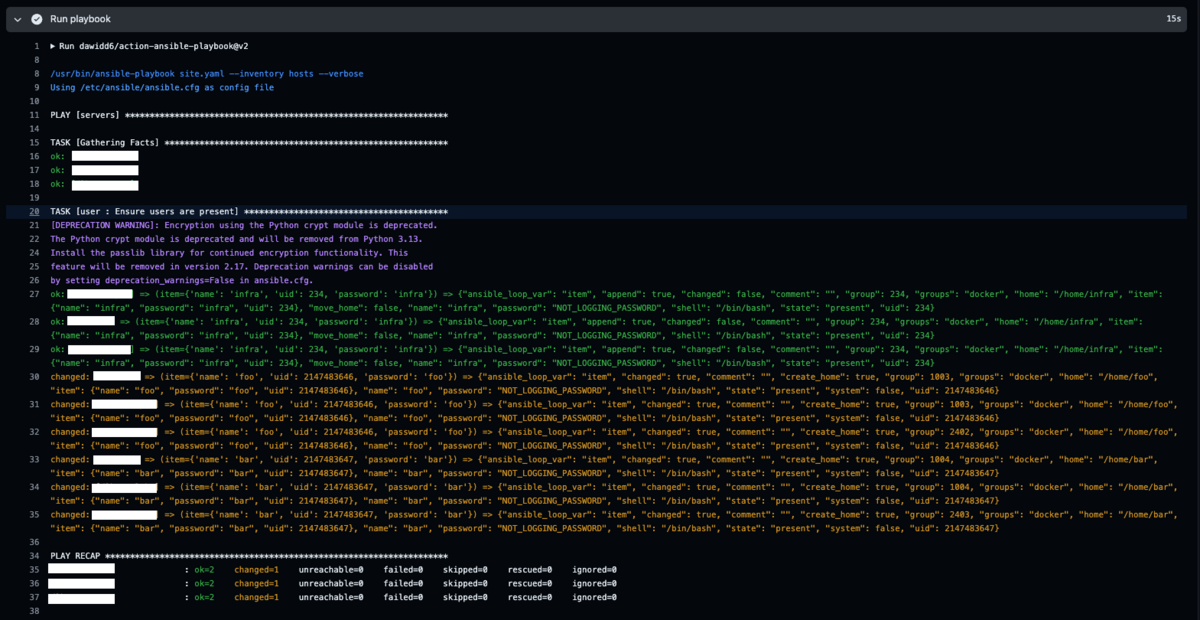
ローカルLLMとしてOllamaを利用したいので、GitHubのドキュメントを参考にしつつ、Ollamaとコンテナ間通信を追加してDocker版でセットアップし直した。今回はLLMとしてLlama 3 8Bを使用した。
# compose.yaml services: anythingllm: image: mintplexlabs/anythingllm container_name: anythingllm ports: - "3001:3001" cap_add: - SYS_ADMIN environment: # Adjust for your environment - STORAGE_DIR=/app/server/storage - JWT_SECRET="************************" # openssl rand -base64 24 - LLM_PROVIDER=ollama - OLLAMA_BASE_PATH=http://ollama:11434 - OLLAMA_MODEL_PREF=llama3 - OLLAMA_MODEL_TOKEN_LIMIT=4096 - EMBEDDING_ENGINE=ollama - EMBEDDING_BASE_PATH=http://ollama:11434 - EMBEDDING_MODEL_PREF=nomic-embed-text:latest - EMBEDDING_MODEL_MAX_CHUNK_LENGTH=8192 - VECTOR_DB=lancedb - WHISPER_PROVIDER=local - TTS_PROVIDER=native - PASSWORDMINCHAR=8 # Add any other keys here for services or settings # you can find in the docker/.env.example file volumes: - anythingllm_storage:/app/server/storage restart: always ollama: image: ollama/ollama container_name: ollama ports: - "11434:11434" volumes: - ollama_storage:/root/.ollama deploy: resources: reservations: devices: - driver: nvidia count: all capabilities: [gpu] volumes: anythingllm_storage: driver: local driver_opts: type: none o: bind device: $HOME/.anythingllm # mkdir ~/.anythingllm ollama_storage: driver: local driver_opts: type: none o: bind device: $HOME/.ollama # mkdir ~/.ollama
起動させたら、ollama runでモデルをダウンロードしつつプロンプトを入力してみる(もちろんollama pullでもOK)。
$ docker compose up -d # 省略 [+] Running 2/2 ✔ Container anythingllm Started 0.8s ✔ Container ollama Started $ docker exec -it ollama ollama run llama3 pulling manifest # 省略 verifying sha256 digest writing manifest success >>> Hello! Hello! It's nice to meet you. Is there something I can help you with, or would you like to chat? >>> /bye
Webブラウザで<サーバーのIPアドレス>:3001にアクセスすると、Anything LLMを利用できる。
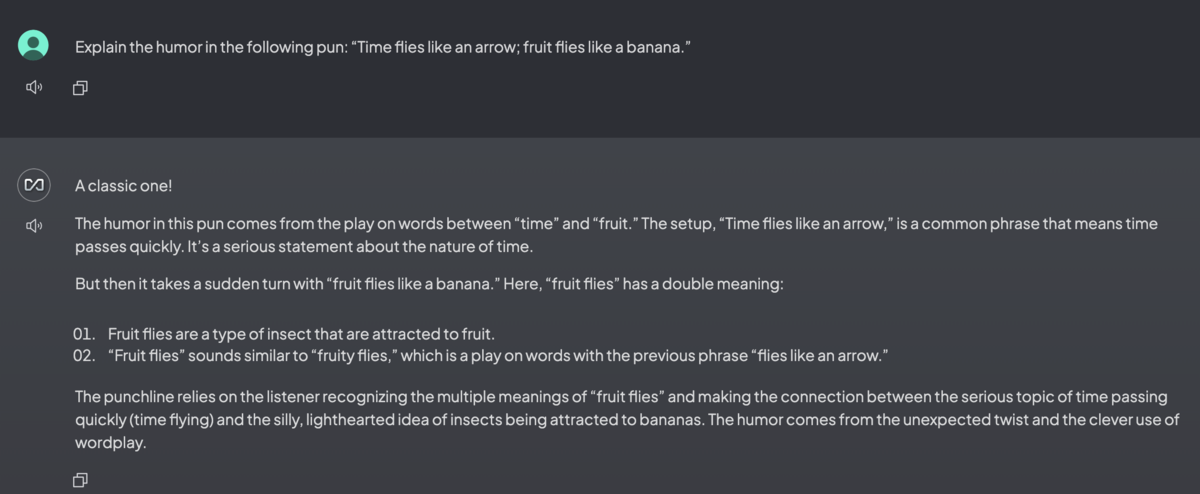
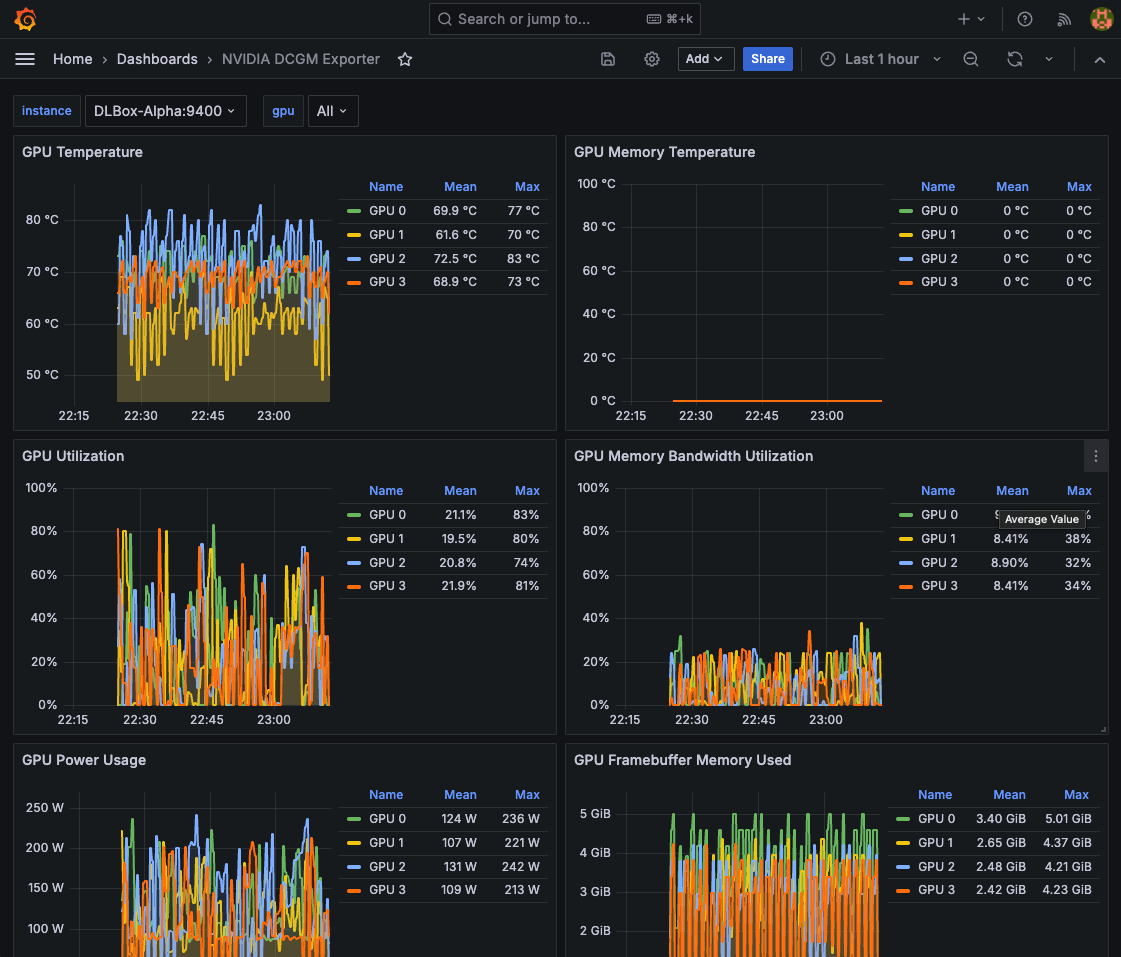
GPU*1を使用した場合、上図のような簡単な質問に対しては1~2秒くらいで回答が返ってきた。
GitHubリポジトリを丸ごとインポートしてWorkspaceにドキュメントとして移動させつつ、特定のファイルをピン留めして質問することもできた。
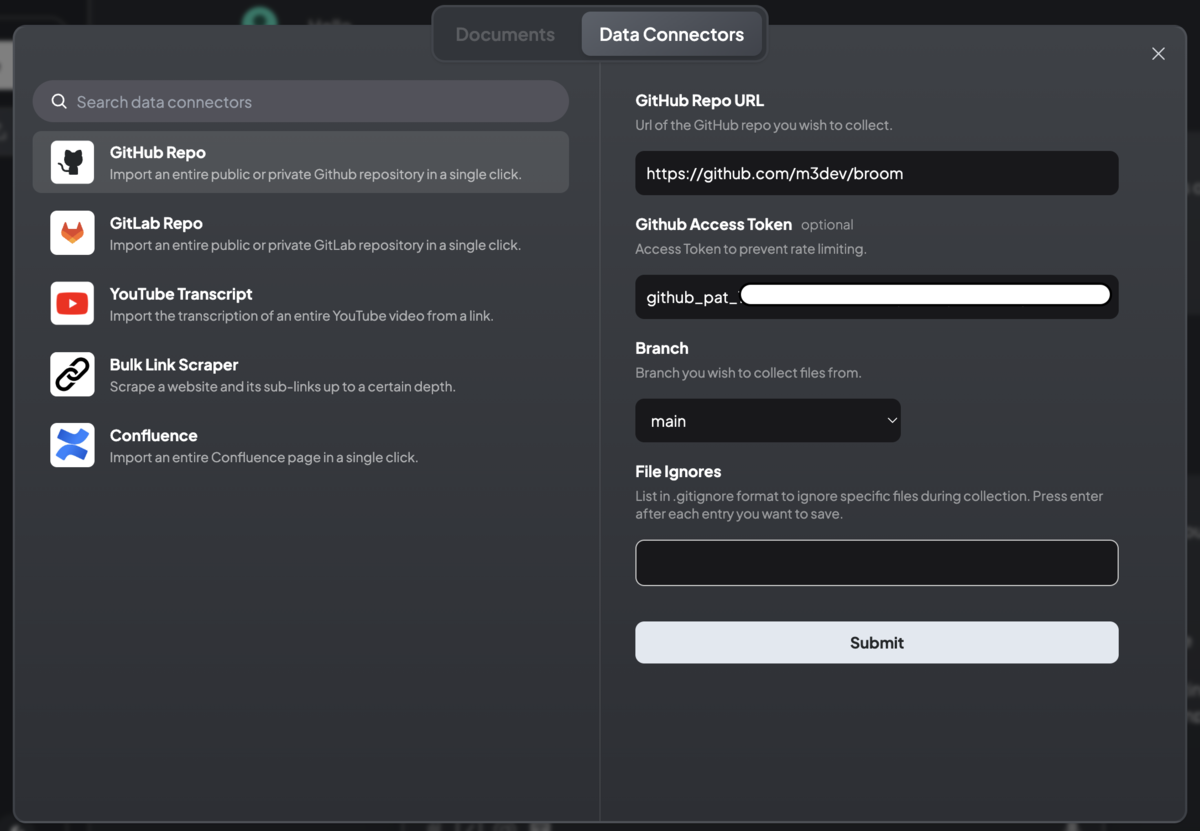
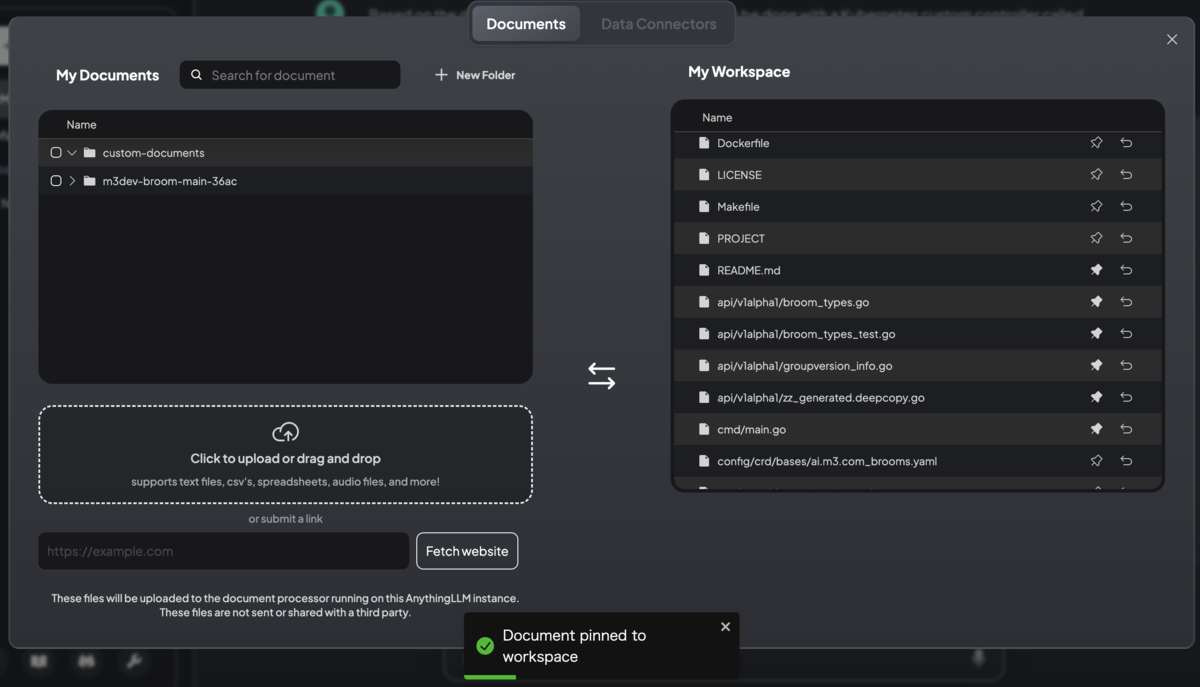
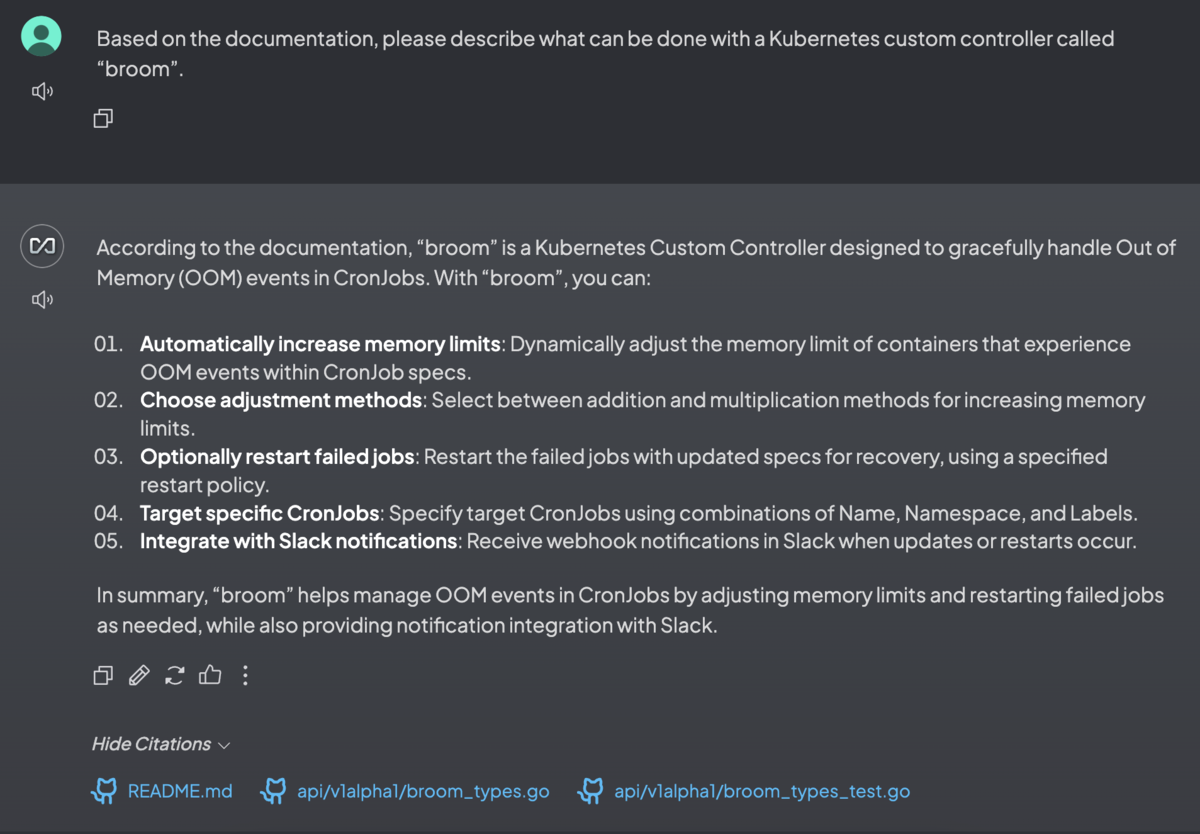
「My Documents」モーダルからファイルをアップロードする場合は問題なかったが、ChatGPTのようにチャット画面の📎ボタンからファイルをアップロードするとなぜか正しく送信できなかった。
感想:マルチユーザーもサポートされており、(マシンリソースがあれば)研究室でセルフホストするのに最適だと感じた。
2. lobehub/lobe-chat
概要:モダンなデザインが特徴であるAIチャットフレームワークで、検索・要約などの便利なプラグインシステムや、〇〇アシスタント・××エキスパートなどが揃う(GPTsライクな)エージェントストアが利用できる。
手順:
Google AI用の環境変数を指定してDockerでデプロイしてみる。事前にGoogle AI Studioで無料のAPIキーを取得しておく必要がある。
取得したAPIキーを利用して、Macbookで以下のコマンドを実行しコンテナを起動する。
$ docker run -d -p 3210:3210 \ -e ENABLED_OPENAI=0 \ -e GOOGLE_API_KEY=*************************************** \ --name lobe-chat \ lobehub/lobe-chat

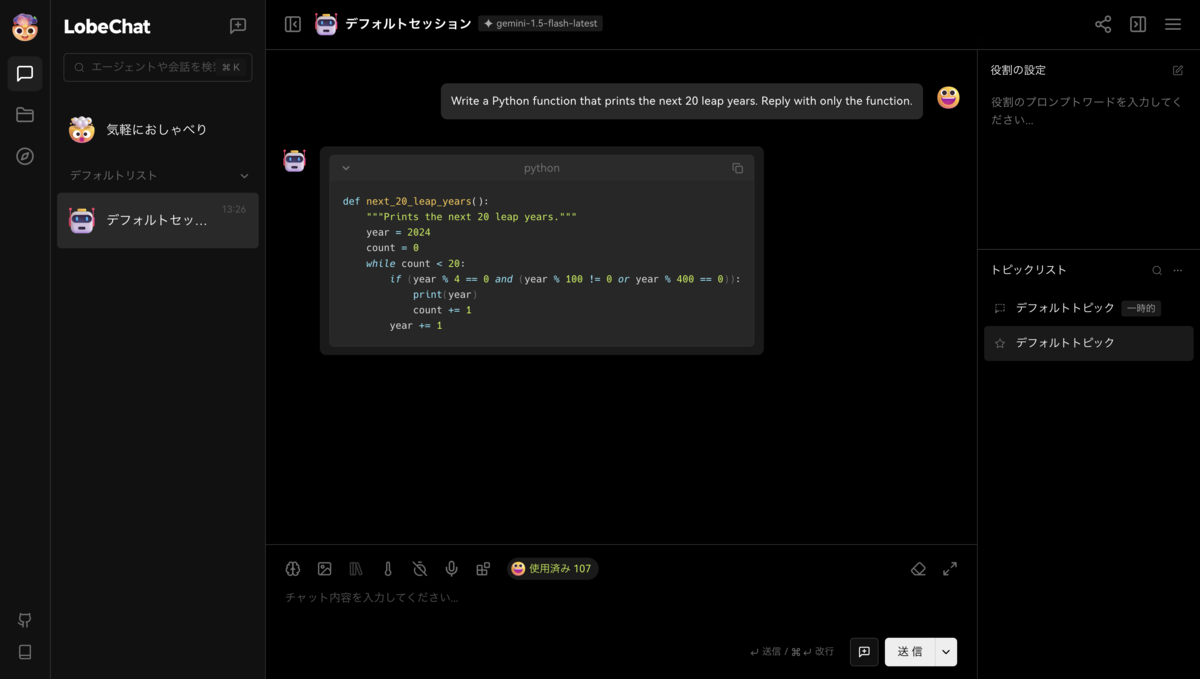
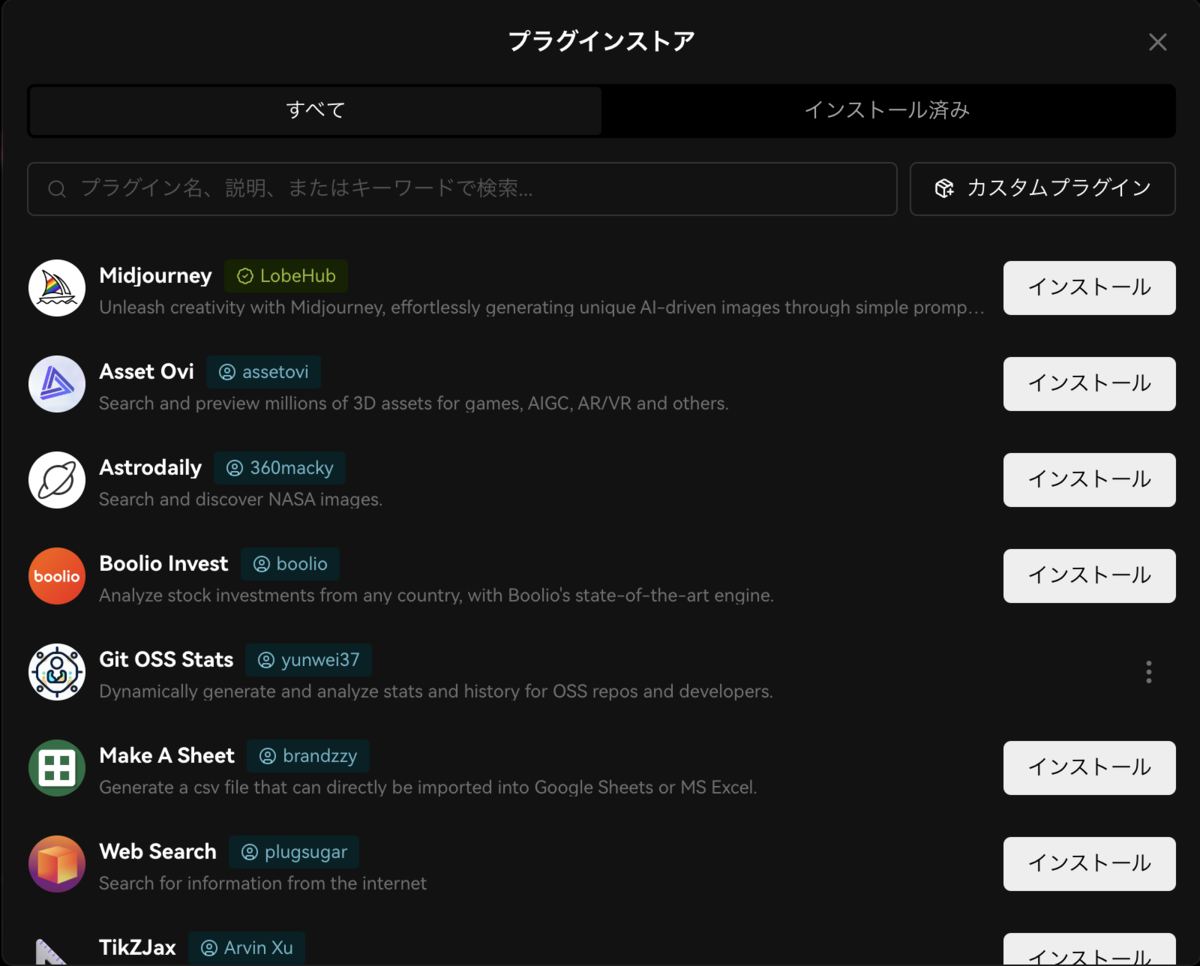
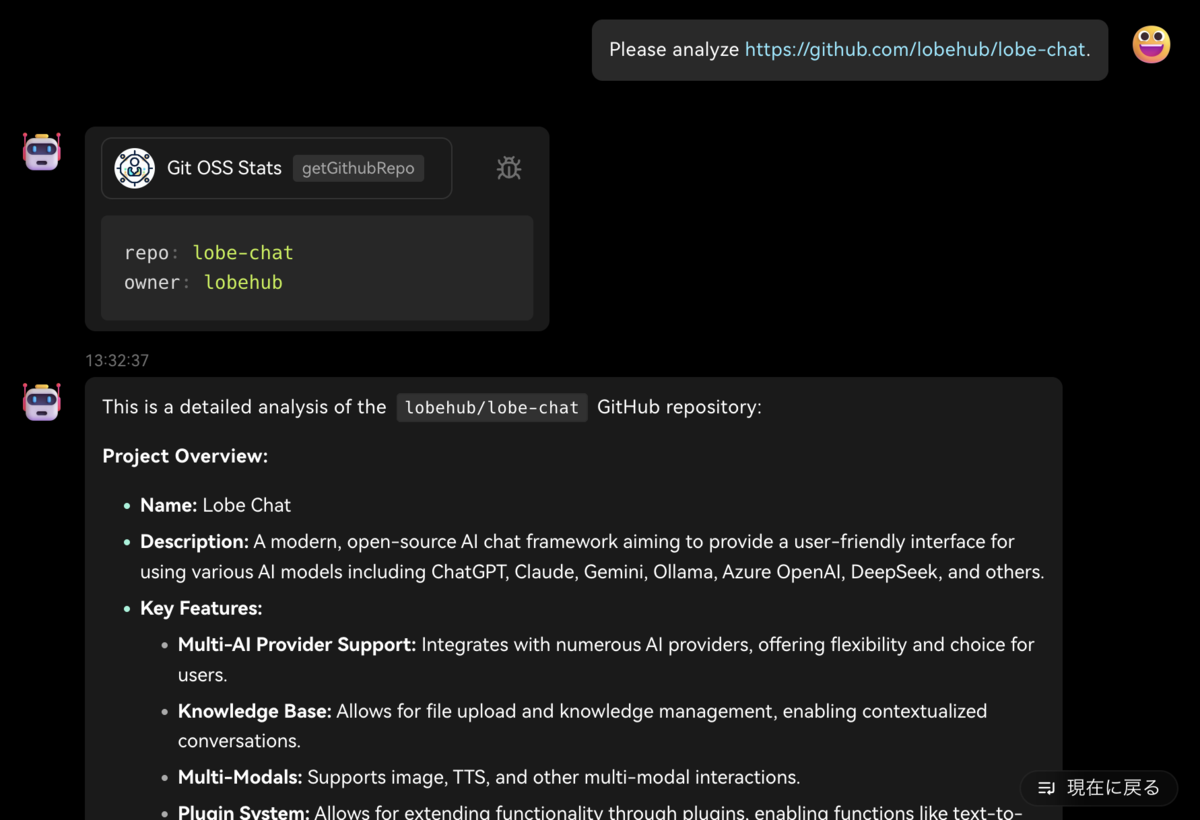

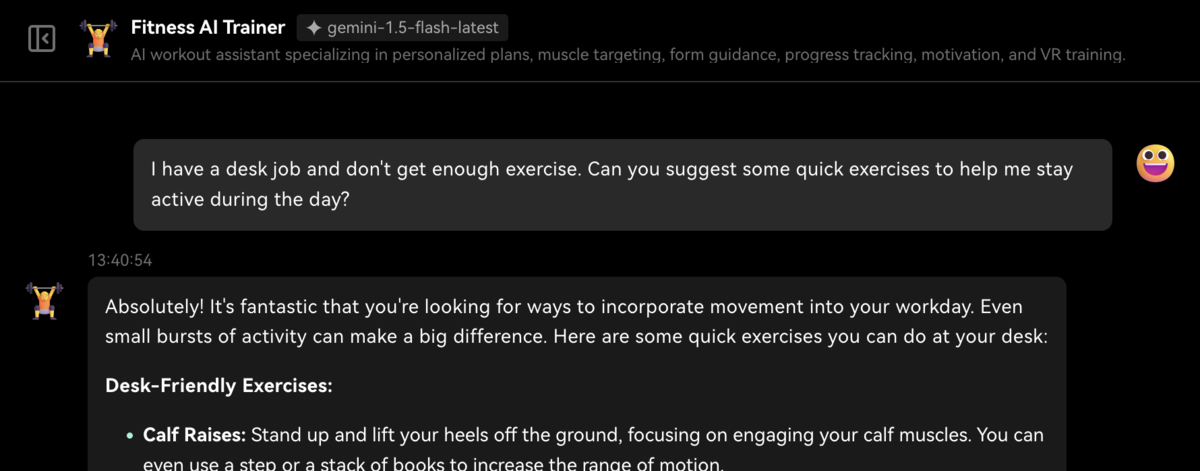
感想:プラグインとアシスタントはお気に入りを探したくなるし、全体的にUIが洗練されていて非常に使いやすかった。
3. OpenBMB/MiniCPM
概要:マルチモーダルLLM(入力:画像&動画&テキスト、出力:テキスト)であり、画像理解でGPT-4o miniやGemini 1.5 Proなどを上回る。
手順:
NVIDIA GPUの場合、以下の手順で実行すればREADMEが前提としている最低限の環境構築ができる。
$ docker run -it --rm --gpus all nvidia/cuda:12.6.1-cudnn-devel-ubuntu22.04 /bin/bash $ apt-get update && apt-get install -y git vim wget $ mkdir -p ~/miniconda3 && wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh && bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3 && rm ~/miniconda3/miniconda.sh && ~/miniconda3/bin/conda init bash && source ~/.bashrc
ただし、[Install]の手順だけではFlashAttentionが入っていないとエラーが出てしまうので、[Multi-turn Conversation]を実行する前にpip install flash-attn --no-build-isolationする必要がある。
実際に約17GBのGPUメモリで1番高性能なモデルが動かせて、推論自体は画像&質問を入力する場合5秒ほど、それを履歴として追加質問をする場合に3秒ほどだった。


感想:iPad Proでモデルを動かしているデモ動画が印象的だった。
4. ollama/ollama
概要:Goで書かれた言わずと知れたローカルLLMの実行ツール。
手順:
今回はGemma 2 27B(16GB)をNVIDIA GPUとDockerで動かしてみた。質問はLLM Benchmarksを参考にした。
$ mkdir ollama $ docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama $ docker exec -it ollama ollama run gemma2:27b # 省略 success >>> Argue for and against the use of kubernetes in the style of a haiku. ## For Kubernetes: Orch, scale, deploy fast. Containers dance, self-healing. Power flows, unbound. ## Against Kubernetes: Complex beast to tame. Learning curve, steep as a cliff. Simpler paths exist? >>> Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have? Sally has **2** sisters. Here's why: All three of Sally's brothers share the same two sisters – Sally and her other sister. Let me know if you'd like to try another riddle!
ローカルLLMとして十分すぎる性能と速度が出た。8KトークンのGemma 2よりも長いコンテキストを扱える128KトークンのQwen2.5などを含む、非常に多くのモデルをサポートしている(library)。
GGUF形式やSafetensors形式のモデルのインポートもサポートされている。
Modelfileというファイルを作成してプロンプトをカスタマイズすることもできるので、以下のようなファイルを作成してモデルを動かしてみた。
FROM gemma2:27b # set the temperature to 1 [higher is more creative, lower is more coherent] PARAMETER temperature 1 # set the system message SYSTEM """ You are Goku from Dragon Ball. Answer as Goku, the assistant, only, and respond exclusively in Japanese. """
今回は扱わなかったが、ADAPTERを指定すれば(Q)LoRAアダプターをモデルに適用できる。
$ docker cp Modelfile ollama:/tmp/ $ docker exec -it ollama /bin/bash $ cd /tmp $ ollama create goku -f ./Modelfile $ ollama run goku >>> がんばれカカロット...おまえがナンバー1だ!! おおおお!ありがとう!お前も頑張れ! Saiyanのプライドを胸に、最強を目指して突き進むぜ!🔥💪
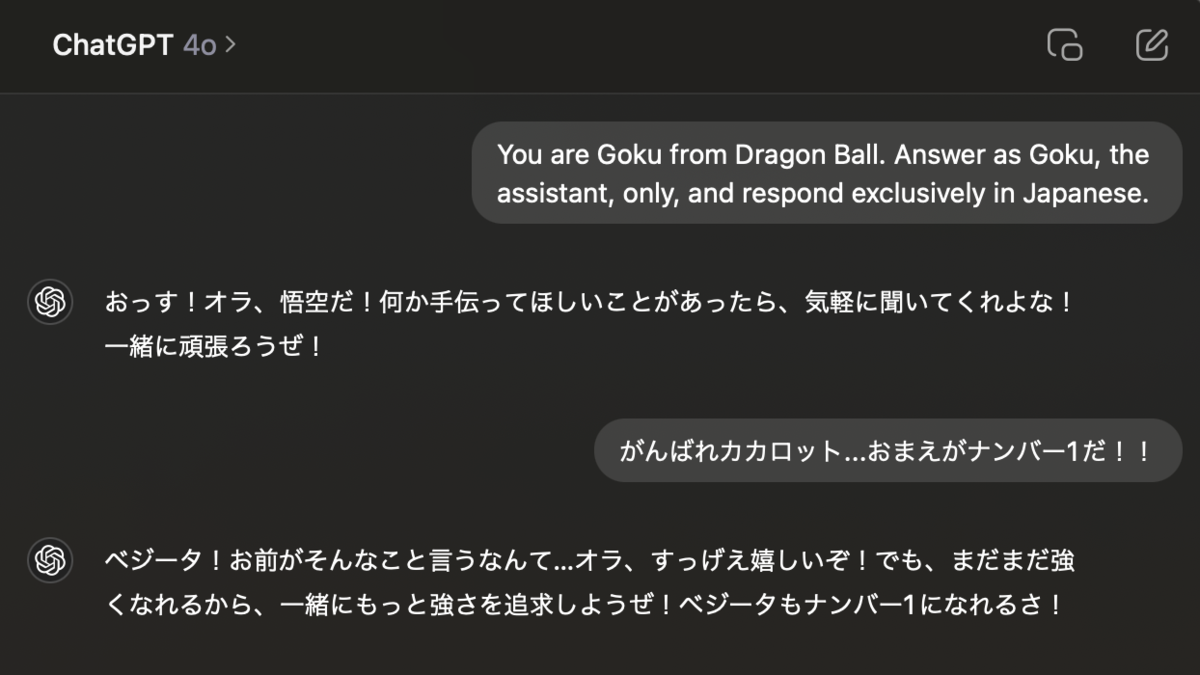
感想:単純にモデルを動かす以外にも、インポートや豊富なカスタマイズができて便利なのでもっと深掘りしてみたい。
5. f/awesome-chatgpt-prompts
概要:ChatGPTをより良く使うためのプロンプト集。
手順:
READMEに「Act as a 〇〇」のプロンプト例が大量に並んでいる。
〇〇として、Linux Terminal、English Translator and Improver、Math Teacher、Prompt Generator、Prompt Enhancer、Python interpreterなど普段から利用できそうなものから特定の職業・ドメインに成り切るものまで揃っていた。
「Act as a Regex Generator」を検証してみる。
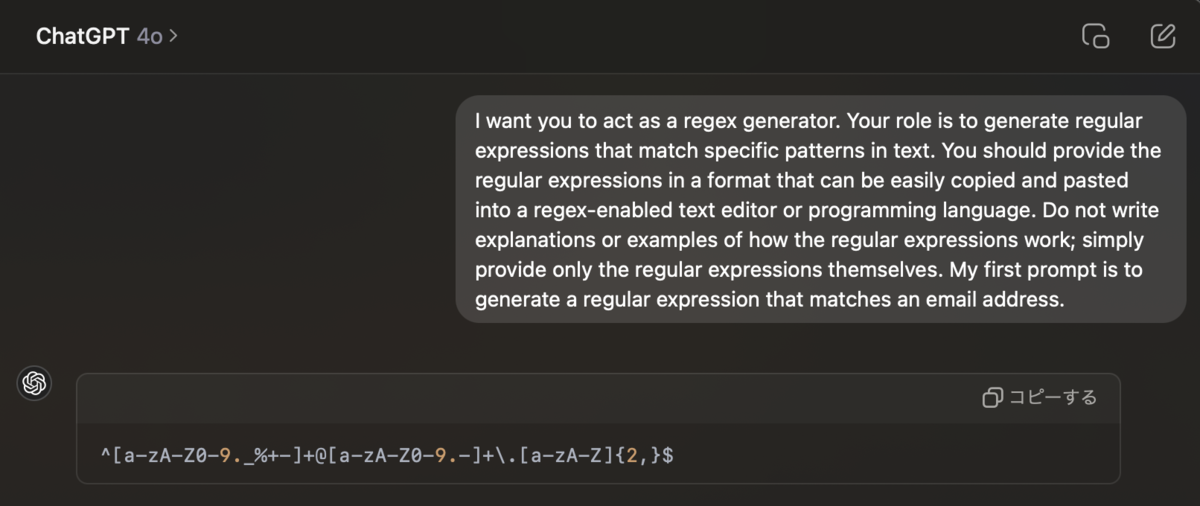
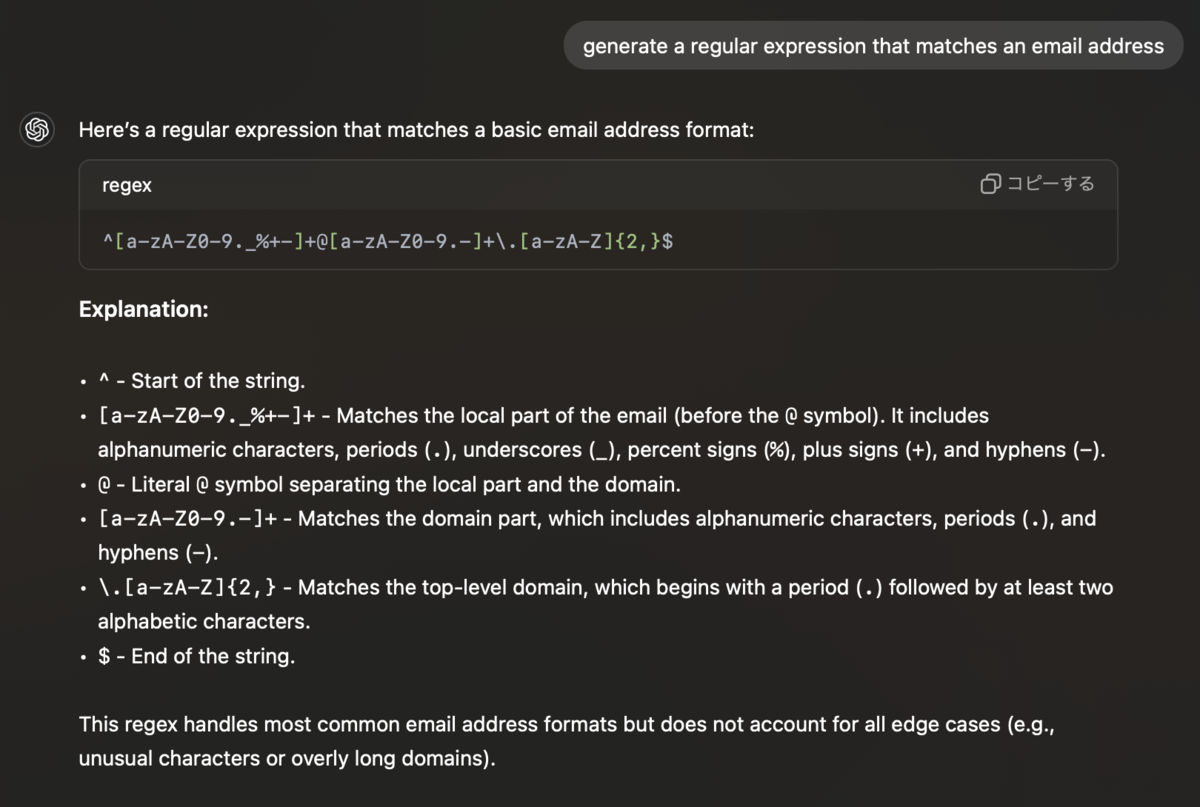
どちらも得られる正規表現は同じだが、サービスの中にLLMを組み込む際には「Do not write explanations or examples of how the regular expressions work; simply provide only the regular expressions themselves.」のようなプロンプトが必要であり、ケーススタディを通してその雰囲気を感じることができた。
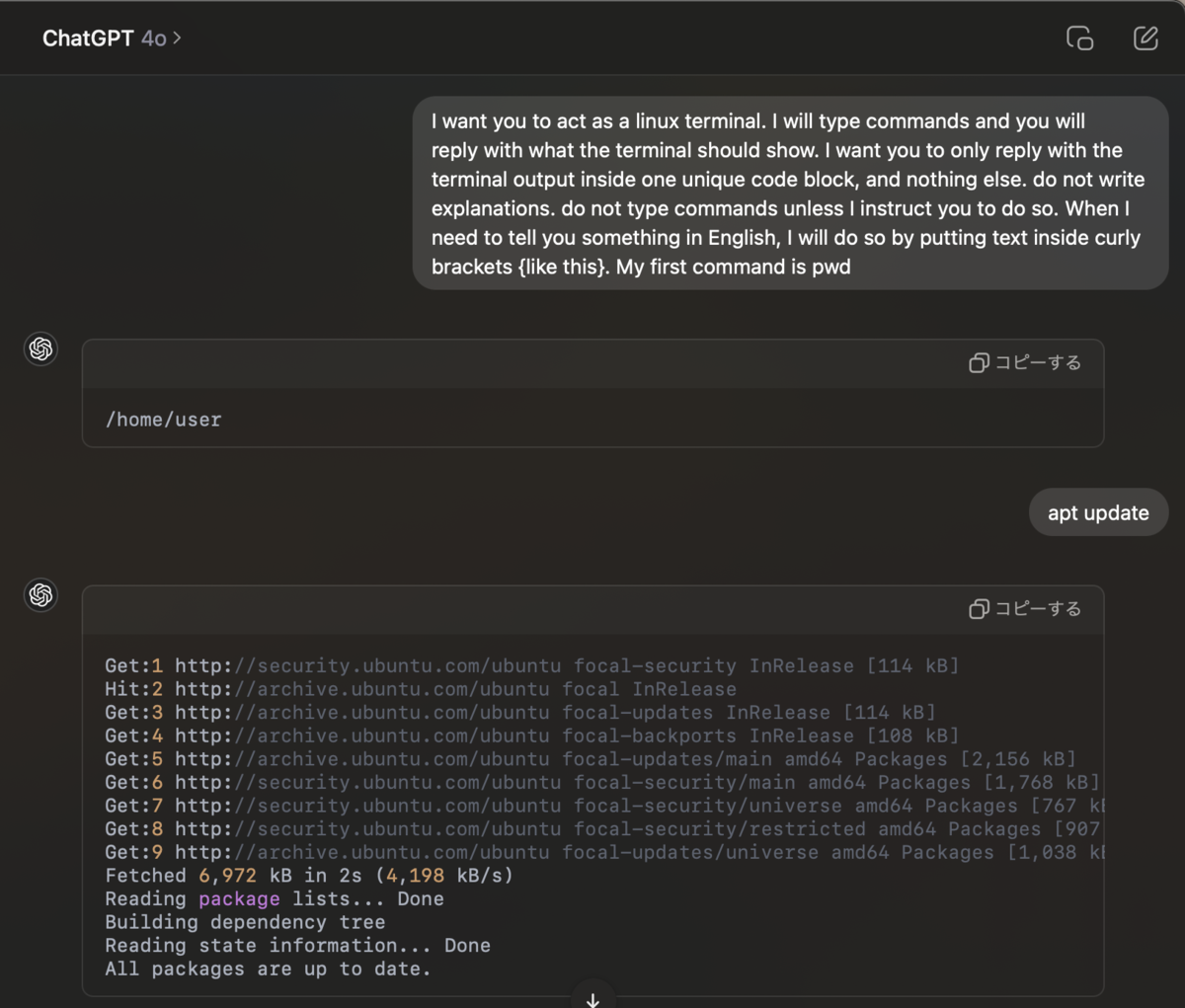
感想:遊んでいるだけで面白かったし、プロンプトエンジニアリングのモチベーションが上がった。
6. mem0ai/mem0
概要:ユーザー・セッション・エージェントレベルで記憶を保持し、ユーザーとの対話を通して適応的にパーソナライゼーションを実現できるAIのメモリレイヤー。
手順:
ドキュメントにあるカスタマーサポートエージェントの例をアレンジして検証した。
様々なLLMやEmbeddier(LLMの種類よりもやや少ない?)をサポートしているが、今回はOpenAIを使用した。
$ docker run -d -p 6333:6333 qdrant/qdrant $ python -m venv venv $ . ./venv/bin/activate $ pip install openai mem0ai $ vim main.py # ドキュメントのコード例をコピー&ペースト $ python main.py I'm sorry to hear that your order hasn't arrived yet. I'd be happy to assist you in resolving this issue. Could you please provide me with your order number and any other relevant details?%
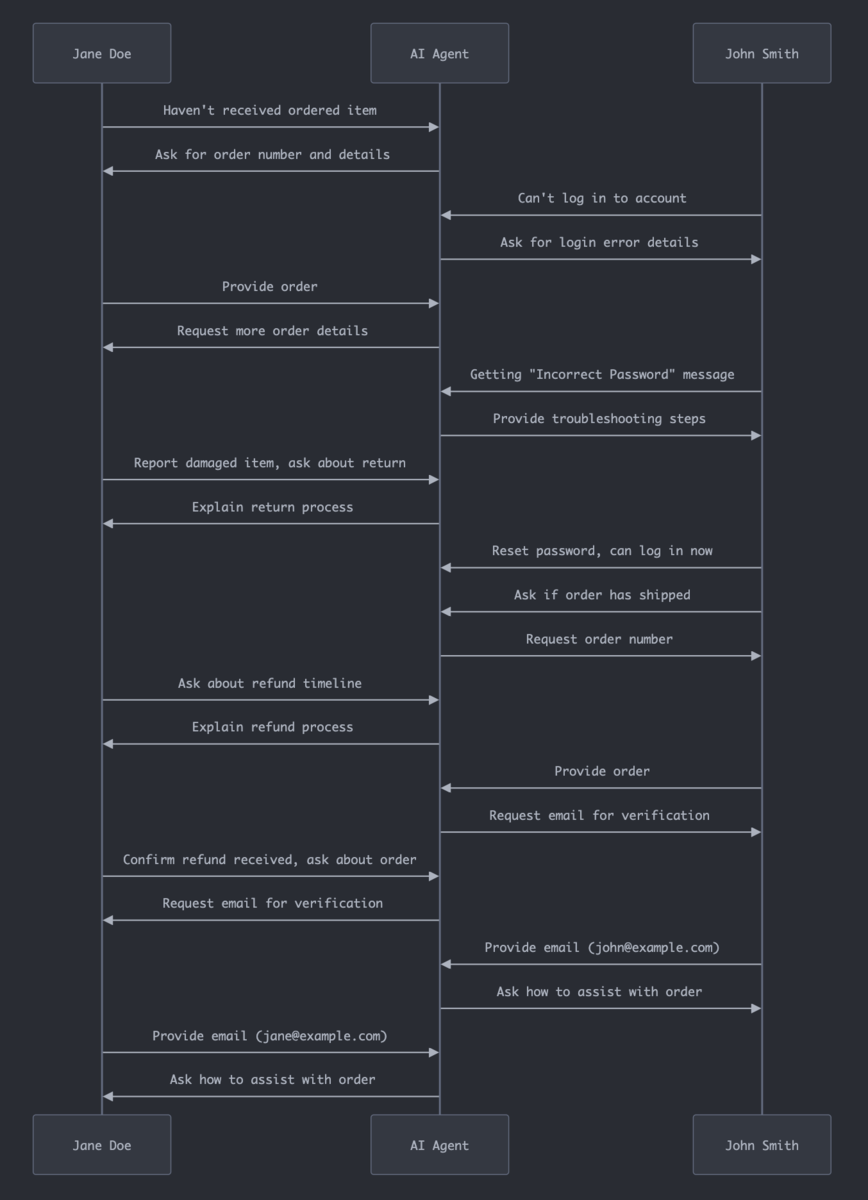
コード例のクエリを実行してもユーザーレベルで過去の記憶が保持されているか分かりにくかったので、Pythonの対話モードを使用して2人がそれぞれ途中で別のコンテキストを挟みながらサポートを受けるシミュレーションを行った。
Results of the Multiple Customer Queries Version …
Jane Doeが最初に#12345の注文が届かないと問い合わせているが、最後に#12345について問い合わせると「How can I assist you with your order today, Jane?」と聞き返されており記憶が不十分だった。
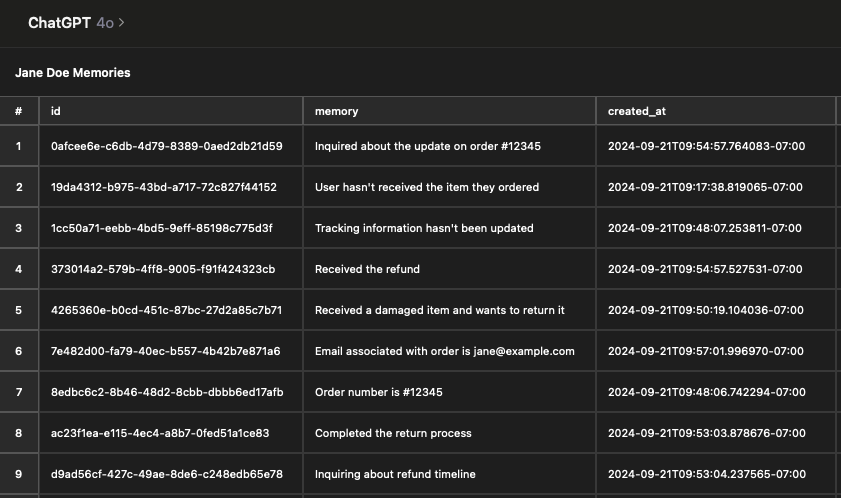
また、メモリの内容を確認したところ予想よりも少なく、サイズを調整できるのか気になった。
感想:ユースケースとしてカスタマーサポートやヘルスケア、生産性管理などが挙げられていて需要が大きいと感じた反面、今回のような複雑なクエリに対する例はドキュメントでも紹介されておらず性能評価が重要だと考えた。
7. ComposioHQ/composio
概要:AIエージェントと100以上のアプリケーション(GitHub、Slack、Gmailなど)を連携するためのプラットフォーム(ツールセット)。
手順:
🚀 Quick Start - ComposioでPythonを選択し、GitHubリポジトリにスターを付けてみる。
$ python -m venv venv $ . ./venv/bin/activate $ pip install composio_core composio_openai $ composio add github #省略 ✔ Authenticated successfully! > Adding integration: Github... #省略 ⚠ Waiting for github authentication... ✔ github added successfully with ID: ********-****-****-****-************
Composioのアカウント(無料)を持っていなかったので作成してから、GitHubの認証を行った。
以下のコマンドで使用するCOMPOSIO_API_KEYはログインした状態でhttps://app.composio.dev/settingsから取得できる。
$ vim main.py # 公式ドキュメント通り $ COMPOSIO_API_KEY=*** OPENAI_API_KEY=sk-*** python main.py [2024-09-24 12:57:47,298][INFO] Logging is set to INFO, use `logging_level` argument or `COMPOSIO_LOGGING_LEVEL` change this [2024-09-24 12:57:52,519][INFO] Executing `GITHUB_ACTIVITY_STAR_REPO_FOR_AUTHENTICATED_USER` with params={'owner': 'composiohq', 'repo': 'composio'} and metadata={} connected_account_id=None [2024-09-24 12:57:53,919][INFO] Got response={'successfull': True, 'data': {'details': 'Action executed successfully'}, 'error': None} from action=<composio.client.enums._action.Action object at 0x112a780e0> with params={'owner': 'composiohq', 'repo': 'composio'} [{'successfull': True, 'data': {'details': 'Action executed successfully'}, 'error': None}]
Quick Startの2はGoogle Calendar、3はGmailだが、時間の都合でスキップした。
感想:認証やフレームワークが抽象化されていてツールごとの開発を行わなくて良いため大幅なスピードアップにつながると感じた。
8. langflow-ai/langflow
概要:Pythonベースのローコードアプリケーション構築ツールで、RAGやマルチエージェントAIをドラッグ&ドロップで作成できる。
手順:
クラウドサービスやHugging Faceスペースも提供されているが、ローカルで試してみた。
公式ドキュメントに従ってpipでインストールしてLangflowサーバーを起動する。
$ pip install langflow -U $ langflow run Starting Langflow v1.0.18... # 省略 ╭───────────────────────────────────────────────────────────────────╮ │ Welcome to ⛓ Langflow │ │ │ │ │ │ Collaborate, and contribute at our GitHub Repo 🌟 │ │ │ │ We collect anonymous usage data to improve Langflow. │ │ You can opt-out by setting DO_NOT_TRACK=true in your environment. │ │ │ │ Access http://127.0.0.1:7860 │ ╰───────────────────────────────────────────────────────────────────╯
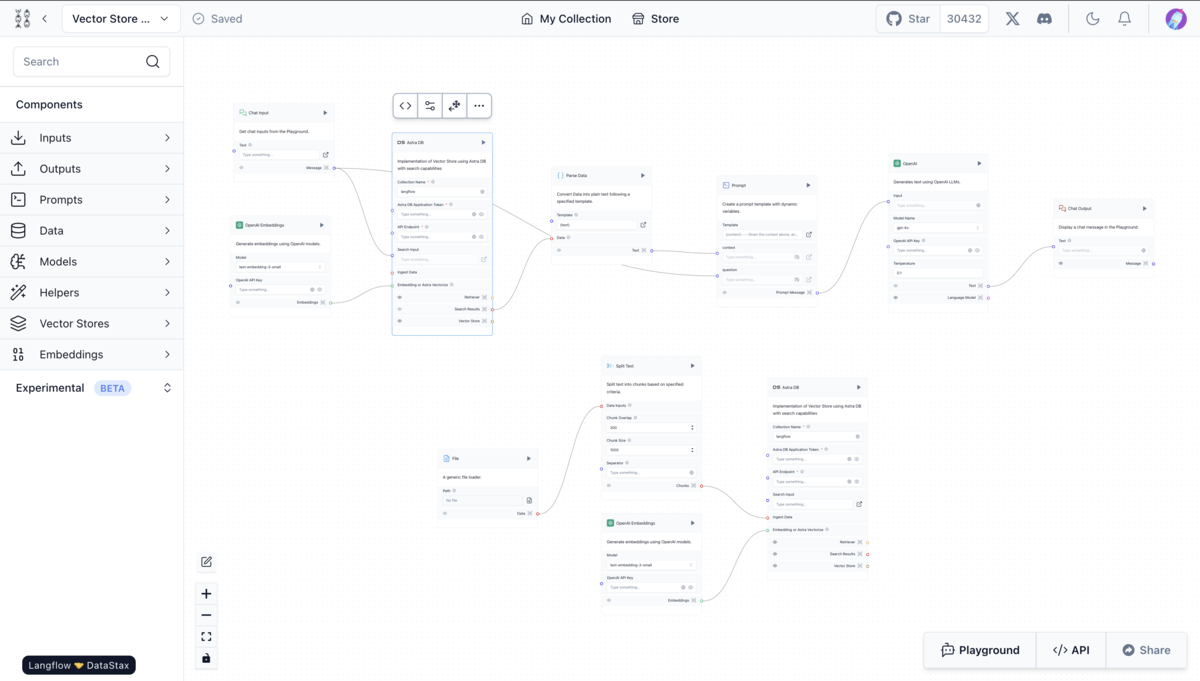
OpenAIのAPIキーを入力するだけで試せると思ったが、デフォルトのベクトルDBにAstraDBというサーバーレスサービスがセットされていて面倒になってしまったのでスキップした。
感想:Difyに似ているものの、チャットのメモリ管理周りのドキュメントが整備されていて他のツールと差別化できている印象だった。
9. comfyanonymous/ComfyUI
概要:Stable Diffusionなどの拡散モデルのパイプラインを実行できるバックエンドを含むGUIツール。
手順:本記事ではLLMにフォーカスするため、省略。
感想:全然ドキュメントを読めていないが、バックエンドをGPUマシン、GUIをMacBookで触ることができれば理想的だと思った。
10. langgenius/dify
概要:直感的なインターフェイスでAIワークフローやRAGパイプライン、エージェント機能など構築できるLLMアプリ開発プラットフォーム。
手順:
READMEにしたがって、以下のコマンドでローカルDifyサーバーを立てた(docker-compose.yamlの中身には、フロントエンド、バックエンド、DB、Redis、Nginx、ベクトルデータベース、MinIOなどが含まれていた)。
$ git clone https://github.com/langgenius/dify.git $ cd dify/docker $ cp .env.example .env $ docker compose up -d
http://localhost/installからWeb UIの「管理者アカウントの設定」に案内された。Getting Startedとしては公式ドキュメントよりも以下の記事が分かりやすかった。
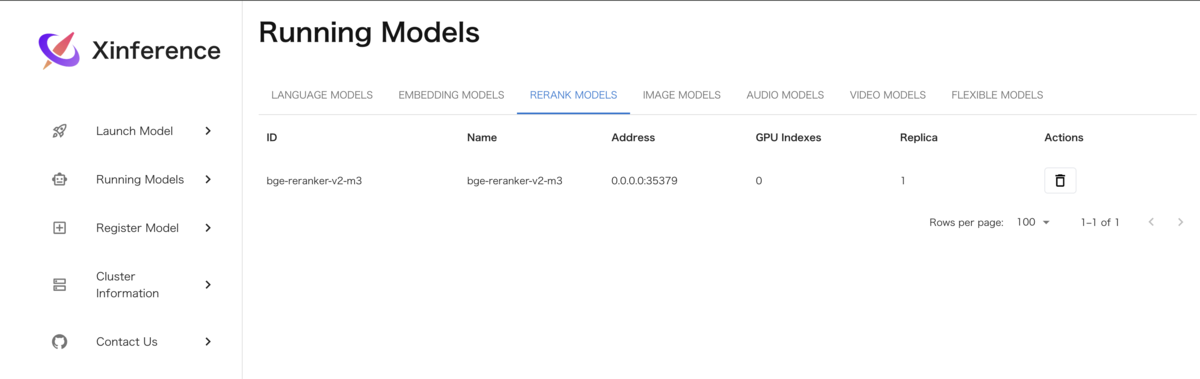
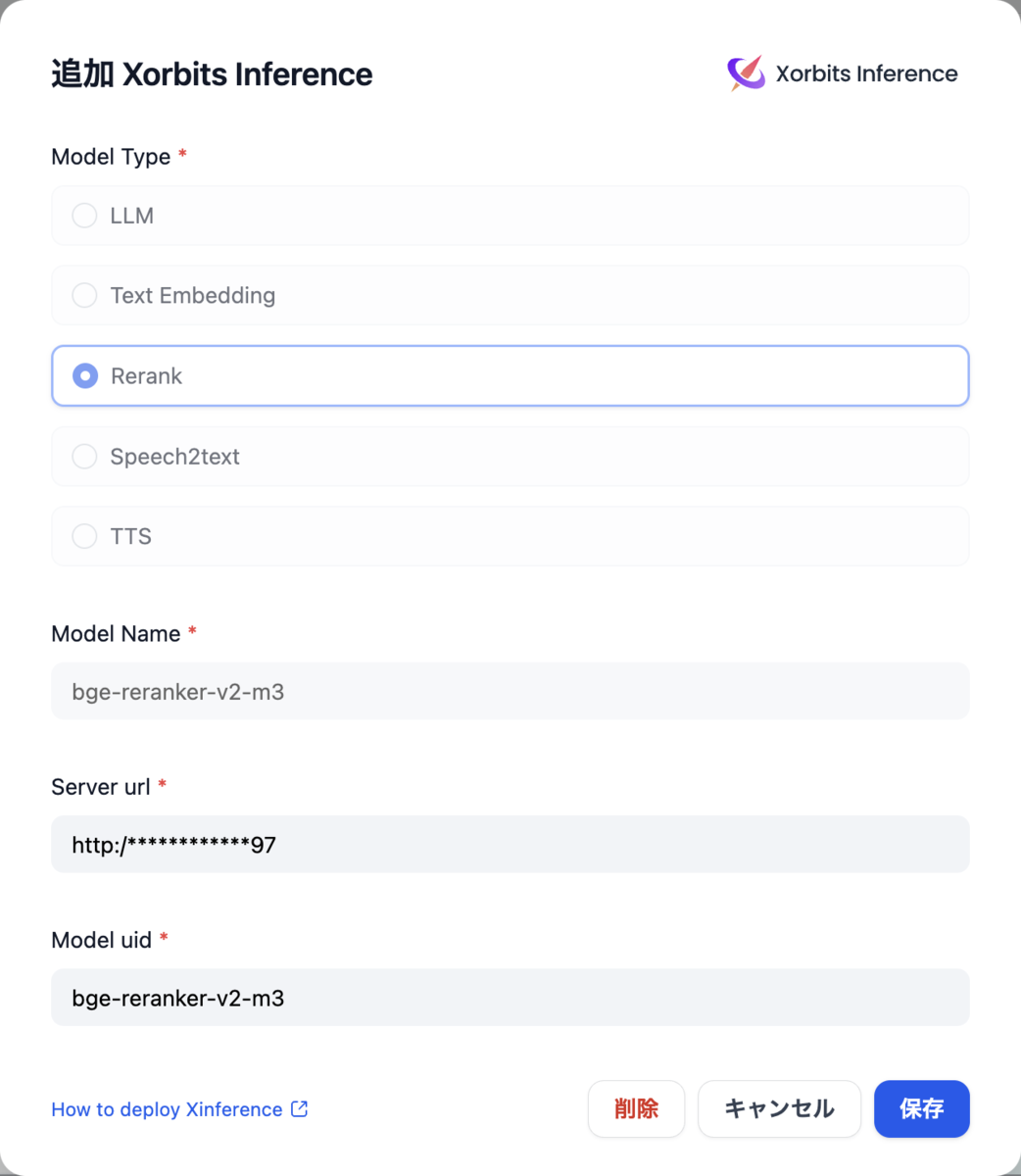
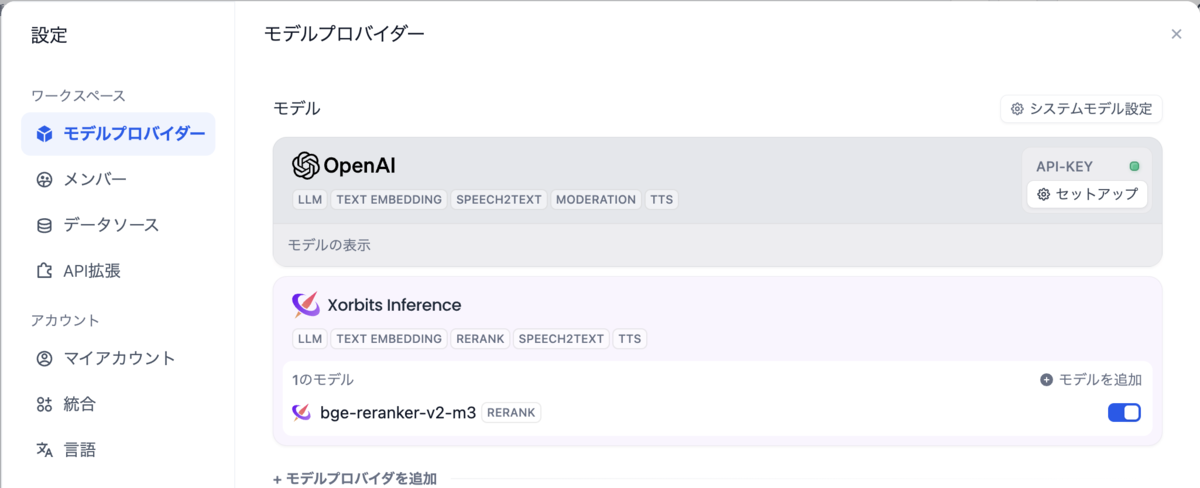
注意点として、記事ではRerankモデルとしてCohereのAPI(有料)が利用されていたため、代わりにローカルGPUマシンでXInferenceサーバーをDockerでセットアップしてbge-reranker-v2-m3というモデルを起動した。
$ mkdir ~/.xinference $ docker run --name xinference -d -p 9997:9997 -e XINFERENCE_HOME=/data -v $HOME/.xinference:/data --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0 # <実行したサーバーのIPアドレス>:9997 から起動するモデルを選択する
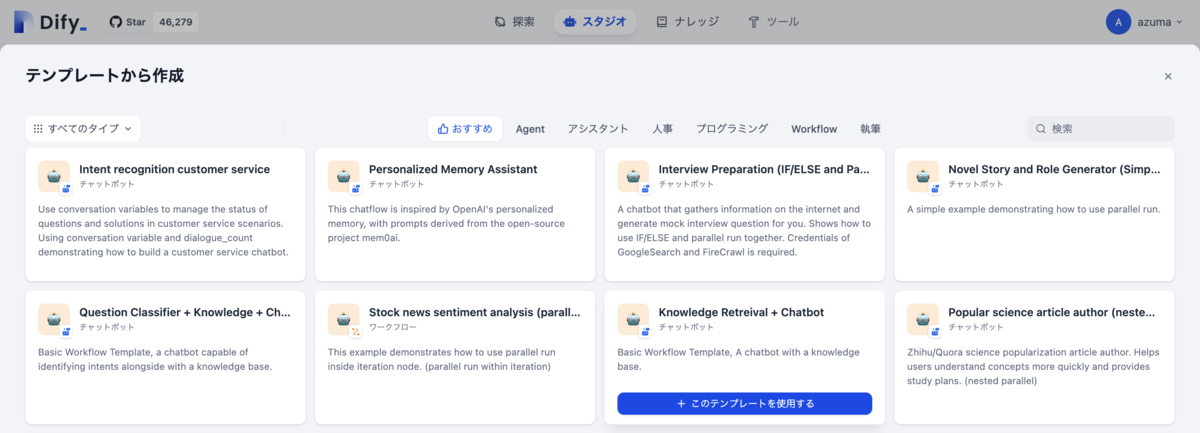
記事のようにゼロからワークフローを構築しても良いが、便利なテンプレートが多数用意されているので今回は「Knowledge Retreival + Chatbot」を使用した。
記事の通りにナレッジを作成(今回はDetaGemmaのテクニカルペーパーを使用)して、「Knowledge Retrieval」ノードの「ナレッジ」として追加することで簡単にRAGを構築することができた。
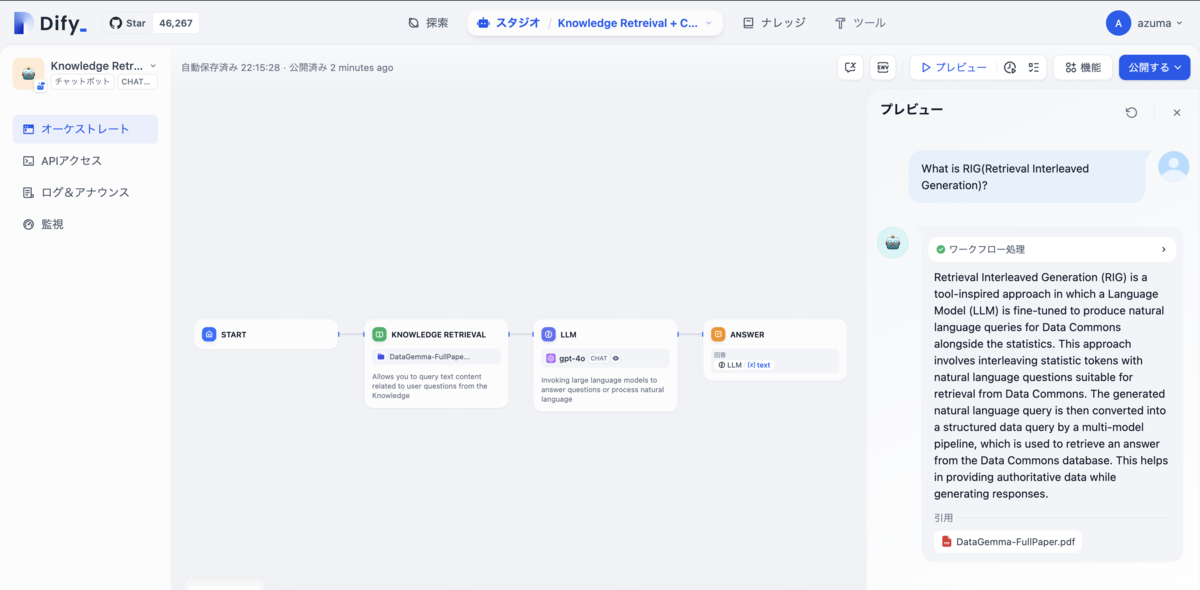
Difyはこの時点で、「アプリ上での直接実行」「ウェブサイト埋め込み」「APIアクセスのセットアップ」が完了しているだけでなく、モニタリング用のダッシュボードも既に用意されていた。
# APIリクエストの例 $ curl -X POST 'http://localhost/v1/chat-messages' \ --header 'Authorization: Bearer <YOUR_API_KEY>' \ --header 'Content-Type: application/json' \ --data-raw '{ "inputs": {}, "query": "What is Data Commons?", "response_mode": "streaming", "user": "azuma" }'; #省略 data: {"event": "node_finished", "conversation_id": "acecb1f4-cc0a-4d16-8ced-f66956e19c67", "message_id": "540c1696-3511-494f-97ab-b177d2bad0ca", "created_at": 1727147646, "task_id": "ed4b7547-7b65-4117-9823-f94df5fc8b2f", "workflow_run_id": "44919eb1-2702-41a8-81cf-2df1a7c24748", "data": {"id": "51693827-de76-40ad-b292-2b32d3126cf4", "node_id": "1711528915811", "node_type": "knowledge-retrieval", "title": "Knowledge Retrieval", "index": 2, "predecessor_node_id": "1711528914102", "inputs": {"query": "What is Data Commons?"}, "process_data": null, "outputs": {"result": [{"metadata": {"_source": "knowledge", "position": 1, "dataset_id": "536a3abe-8392-488f-b65d-178ed227f256", "dataset_name": "DataGemma-FullPape...", "document_id": "2efb709e-b967-4cab-88ef-c9f6005a9f1d", "document_name": "DataGemma-FullPaper.pdf", "document_data_source_type": "upload_file", "segment_id": "7ebae28e-ff12-495f-9b99-34c70a897cd7", "retriever_from": "workflow", "score": 0.9980077147483826, "segment_hit_count": 1, "segment_word_count": 1725, "segment_position": 7, "segment_index_node_hash": "ca757a7b80f202a20e26684e64a07655096ff2384ccda5ccab83b1ef8606cb3e"}, "title": "DataGemma-FullPaper.pdf", "content": "formats from only a handful of examples in training data.\r\n9 This paper builds upon LIMA utilizing\r\nsmall set training for RIG and RAG explorations with Data Commons KGs. #省略 #省略
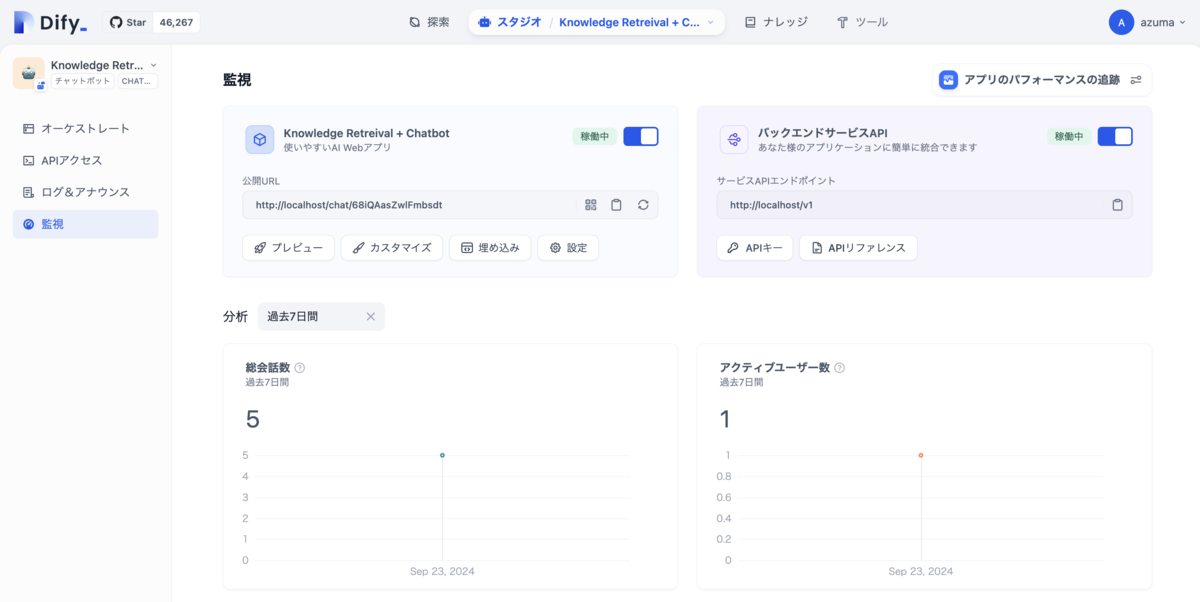
感想:ワークフローには他のノードもあり、変数と組み合わせることでDifyだけでさらに複雑なシステムを構築できるのが魅力だと感じた。
まとめ
トレンドの上位を中心に、手元でLLM関連のOSSを動かしてみました。
LLMの理論は『大規模言語モデル入門』という本を読んで理解することができましたが、プロダクト視点は全く持っていなかったので大まかに雰囲気を掴むことができて良かったです。
特にollama/ollamaはゲームチェンジャーだと思いました。Go実装なので近いうちにソースコードも読んでみたいです。
エンジニアとして流行は常にキャッチアップしたいので、10個とは言わず3個くらい定期的に触る習慣をつけたいです。